새로운 정렬방법에 놀래서 나중에 활용하려고 올림.
sort시 key를 비교방식으로 한다. c++이랑 java에는 있던데 파이썬은 삭제됐더만..
주의할 점은
functools.cmp_to_key(func)의 리턴을 True나 False가 아닌 양수,0,음수로 받는다는 것. 두 비교 결과를 통해 제일 작은 건 맨 앞에, 큰 건 뒤로 오름차순 정렬은 같다.




import sys
import itertools
import functools
sys.stdin = open("sample_input.txt", "r")
def compare_rail(x,y):
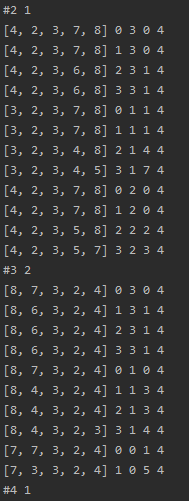
com1 = y[0]*(x[0]+x[1]) + y[1]
com2 = x[0]*(y[0]+y[1]) + x[1]
print(x,y,com1,com2,com1-com2)
return com1-com2
T = int(input())
# 여러개의 테스트 케이스가 주어지므로, 각각을 처리합니다.
for test_case in range(1, T + 1):
# ///////////////////////////////////////////////////////////////////////////////////
N = int(input())
rail = [0] * (N)
for i in range(N):
a,b = map(int, input().split())
rail[i] = (a,b)
# rail.sort(key=lambda x:x[1]-x[0])
cmp = functools.cmp_to_key(compare_rail)
print(rail)
rail.sort(key=cmp)
print(rail)
v = 1
# vc = list(itertools.permutations(rail,r=5))
# print(vc)
for a,b in rail:
v = ((a*v) + b) % 1000000007
print(v)
# v=1
# for r in vc:
# v = 1
# print(r)
# for a, b in r:
# v = (a * v) + b
# print(v)
# print(v % 1000000007)
print("#{}".format(test_case),v % 1000000007)
# ///////////////////////////////////////////////////////////////////////////////////