[Graph 5강] 그래프의 구조를 어떻게 분석할까?

분명 군집은 존재하지만 수학적으로 정의하긴 애매하다. 하지만 어쨋든 정의해야 한다. 그래서 어떻게 하는가? 군집성을 정의해서 이용한다..

여기서 배치 모형(Configuration Model)은 1) 각 정점의 연결성(Degree)을 보존한 상태에서 2) 간선들을 무작위로 재배치하여서 얻은 그래프. 배치 모형에서 임의의 두 정점 i와 j 사이에 간선이 존재할 확률은 두 정점의 연결성에 비례한다.
내가 생각하기엔 그냥 원래 그래프 모양에서 정점들은 그대로 냅두고 간선만 조정하는데, 임의의 간선을 제거하든, 특별한 규칙에 의해 제일 조건을 많이 만족하는 간선을 제거하든 하는 방식으로 어쨋든 간선만 조정해서 만든 것 같다. 그냥 실습 코드 보니까 그런 것 같음.
그렇게 원본 그래프에서 군집 s 내부 간선의 수에 바꾼 거를 빼서 어떻게 점수를 만들어 내는 모양이다. 이 군집성 정의 식에서 식을 통해 나온 결과가 크다는 것은 그래프에서 군집 s 내부 간선의 수가 많다는 걸 뜻하기 때문에 성공한 군집 탐색이라고 한다.



즉, 군집성은 무작위로 연결된 배치 모형과의 비교를 통해 통계적 유의성을 판단합니다.
군집성은 항상 -1과 +1 사이의 값을 갖습니다.
보통 군집성이 0.3 ~ 0.7 정도의 값을 가질 때, 그래프에 존재하는 통계적으로 유의미한 군집들을 찾아냈다고 할 수 있습니다.
그래서 이렇게 군집인지 아닌지 탐색하는 알고리즘이 있는데, 우린 Girvan-Newman 알고리즘, Louvain 알고리즘을 살펴본다.
군집 탐색 알고리즘
Girvan-Newman 알고리즘
원본 그래프는 모두 다 연결되어 있다. Girvan-Newman 알고리즘은 원본 그래프에서 다리 역할을 하는 간선을 제거하는 방식으로 군집을 찾는다. 즉 Top-down 방식이다.
그럼 이 다리역할을 하는 간선을 어떻게 찾아내냐? 간선의 매개 중심성(Betweenness Centrality)를 사용한다. 이는 해당 간선이 정점 간의 최단 경로에 놓이는 횟수를 의미한다.

이 예시 그래프를 보자. 왼쪽에 4개 정점, 오른쪽에 4개 정점이 있다고 하자. 오른쪽에 임의의 두 정점을 보면 두 사이의 정점을 가는 방법이 한 간선 말고도 여러 간선의 방법이 있으니 수가 적다. 반면 왼쪽 정점에서 오른쪽 정점으로 지나려면 필연적으로 중간에 한 개밖에 없는 단선을 지나야 한다. 그래서 저 선의 매개 중심성이 높다고 개념을 잡는거고, 실제 수치적으로도 그럴 수 있도록 수식을 정의하는 것 같다.
차 다니는 도로에서 통행량이 많은 도로가 중간다리 역할을 본다고 생각하는 것과 같은 개념인 것 같다.
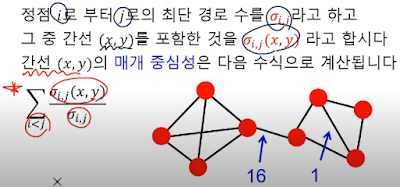



이런식으로 매개 중심성이 가장 많은 간선부터 하나씩 제거하며 군집성을 측정해 제일 높은걸 기준으로 삼는듯.

정리하면, Girvan-Newman 알고리즘은 다음과 같습니다.
1) 전체 그래프에서 시작합니다
2) 매개 중심성이 높은 순서로 간선을 제거하면서, 군집성을 변화를 기록합니다
3) 군집성이 가장 커지는 상황을 복원합니다
4) 이 때, 서로 연결된 정점들, 즉 연결 요소를 하나의 군집으로 간주합니다
즉, 전체 그래프에서 시작해서 점점 작은 단위를 검색하는 하향식(Top-Down) 방법입니다
Louvain 알고리즘
Louvain 알고리즘은 반대로 상향식(Bottom-Up) 군집 탐색 알고리즘이다.
개별 정점으로 구성된 크기 1의 군집부터 시작해서, 군집성이 최대화 되도록 연결하고 증가하지 결정되었으면 각 군집을 하나로 하는 그래프로 만들고 다시 수행하고.. 를 한다.


기준은 역시나 군집성으로 한다.
중첩이 있는 군집 탐색
사실 군집이란게 어느 하나에만 속하는게 아니고 한번에 여러곳에 속할 수도 있다.

정점이 군집 A에 속해있다면, 같은 군집 A에 속해있는 다른 정점과 연결될 확률이 PA 라고 한다. 그러므로 두 정점이 여러 군집에 동시에 속해있을 경우, A군집이든 B군집이든 어쨋든 둘이 간선으로 연결되어있을 확률이 1-(1-PA)(1-PB) 라는 듯. 연결되어 있다면 군집으로 치니까.. 둘다 어디에도 안 속하면 그냥 엡실론의 낮은 확률로 직접 연결되자고 하는 것 같다.



실습
https://colab.research.google.com/drive/1MOVUbS3qijbVFFw7DBfNr_qZ4pF_I6E3?usp=sharing
[Graph 6강] 그래프를 추천시스템에 어떻게 활용할까? (기본)
추천시스템 방법으로 내용 기반 추천시스템과 협업 필터링 방법이 있다.
내용 기반 추천시스템



사용자 프로필과 작품 프로필을 one-hot vector를 이용하여 표시한다. 그럼 작품마다 더해서 평균으로 표시할 수 있는 등의 작업을 할 수 있다. 그래서 사용자 프로필과 작품 프로필간의 유사도를 코사인 각도로 계산 한 후, 최종적으로 추천한다.
작품으로만 추천하기 때문에 그에 따른 장단점이 존재한다. 당연한 것들이다.


협업 필터링 추천시스템
유사한 사람들끼리 비교해서 추천한다. 즉 내가 안보고 나랑 취향이 비슷한 사람이 봤다면 그걸 추천하는 방식이다. 그럼 당연히 어떻게 유사한 사람을 찾는지, 유사도는 어떻게 정의하는지 등등이 필요하겠다.


수학 수식은 저러지만 실제로는 가장 비슷한 사람 5명, 10명 뽑아서 행렬곱셉으로 한번에 sum을 계산하는 방식을 쓰는 것 같다.
비슷한 취향의 사람으로 추천하기 때문에 당연히 그에 따른 장단점이 존재한다.

추천 시스템의 평가
그럼 이렇게 두가지 방법으로 만든 추천시스템이 정말 맞는지 아닌지 평가하는 시스템을 구축할 필요가 있다. 그래야 뭐가 더 자기 시스템에 맞는지 알지.
평가는 실제 존재하는 시스템 평가에서 임의로 몇개빼고 그걸 나머지 평가한 것들을 이용해 고려해서 추측하게 만든 뒤 예측값과 참값의 차이로 평가하는 방식을 사용한다.


이렇게 하는 방식 말고도 다양한 다른 지표를 사용하기도 한단다. 그건
추정한 평점으로 순위를 매긴 후, 실제 평점으로 매긴 순위와의 상관 계수를 계산하기도 합니다
추천한 상품 중 실제 구매로 이루어진 것의 비율을 측정하기도 합니다
추천의 순서 혹은 다양성까지 고려하는 지표들도 사용됩니다
실습
https://colab.research.google.com/drive/1dvVB9Upabv1JxwnSsazLVOq77d0mlbVr?usp=sharing
===================================
과제
내일까지라 지금 하는중..
================================
피어세션
마스터세션에서 질문할 것들 생각해보기
상건: 컴퓨터비전, 자연어처리, 추천시스템 중에 취업에 유리한 분야를 선택한다면 어떤걸 하실건가요? 물론 가장 흥미있는 곳으로 하는게 이상적이겠지만 흥미분야를 아직 잘 모르겠고, 같은 인공지능이라면 충분히 trade-off 할만하다고 생각합니다.
수업내용
상건: 5강 복습함. 군집연결 부분.
상기: 실습6 오래 걸리더라. 6강. 추천이 어디에 사용되는가. 추천원리가 어떻게 되는지 알게됐다. 협업필터링과 내용기반도 있었는데 내용기반은 유사도를 매겨서 one-hot 벡터로 만들고 이걸 코사인 유사도를 이용해서 유사함을 추천. 내용 기반 추천시스템의 장단점에 대해 꼼꼼하게 고민해봄. 협업 필터링에 대해서도. 수업 내용도 복기해보는 시간을 가졌다.
규진: 실습6 오래 안걸리던데..
https://zzaebok.github.io/knowledge_graph/recommender_system/KG_recommend/
content-based filtering은 영화 내용으로만. 작품의 특징으로 하기 때문에 새로운 것도 되고. 근데 collaborative filtering은 유저와 하는거라 영화 특징만으로는 못한다.
배칭모형은 정점들의 연결성을 유지하는거. degree 수만 유지하고 간선은 랜덤으로 하는 것. 평균으로 한다는게 어쨌든 간선으로 연결되어 있으면 하나의 군집으로 치니까 그 군집에서 간선의 개수.
매개 중심성은 특정 거리를 지나는 최단 거리 경우의 수에서 특정 간선을 지나는 경우의 수 만큼의 비율을 계산하는 거 (라고 난 이해함).
연세님 추가설명
관심있는 간선을 얼마나 지나가느냐 의 비율. 관심있는 걸 (x,y)로 작성.
연세: 앞에 (½||E||) 는 뭔가? 아마 정규화 때매 있는 듯. ||E||는 S의 간선의 개수가 아닐까?
루베이방식. bottom-up 방식. 각각의 것들을 집군으로 하고 하는거라던데 실습에서도 안보여주고 해서 잘 이해가 안간다. 중복 군집 유형도 복잡도가 엄청 높을 것 같은데 최적화 된 방법은 없을까.
또 수업시간에 했던 추천시스템에 대해서도 복기를 해보았다.
채원: 어제꺼 복습해보기. 전파과정이 복잡하니까 수학적 모형화를 할 필요가 있따. 의사결정과 확률적이 있는데 의사결정은 행복지수로 예시를 들수도 있고, 임계치로 이웃 수에 따라 전파된다. 확률적은 그냥 확률적으로만. 서로 감염시킬 확률이 독립적이다. 최초 감염자( 시드집합, 얼리어뎁터) 들이 중요함. 얘내를 고를때는 전파 최대화 문제, 시드집합을 구한다. page rank는 학교에서 배웠던 거랑 비슷한 듯. greedy algorithm도 시드 전파자를 하나 하나 찾아 가는거다. 최저 성능이 수학적으로 보장이 되어 있다. 구체적으로는 왜인지 모르겠지만…
정훈: np-hard 그 얘기는 알고리즘 문제를 풀 수 있는 문제중에서 구분한 거 같은데 NP-hard는 문제는 풀지마라 라고 배움.
협업필터링 유사도식. 익숙한 형태. 상관계수 구하는거.
난 재밌었다. 자료구조에 불과했던게 추천까지 이어지는게..
추천시스템의 작동원리가 어떻게 되는지 몰랐는데 유사도 측정을 이렇게 하고 저렇게 해서 묶어주는구나.. 신기했다.
top-down, bottom-up 연산 관점에서 생각은 못했는데 다시 한번 생각해봤다.
기타내용:
규진: KDT 는 kaggle https://www.kaggle.com/c/riiid-test-answer-prediction 에서 했던듯.
추천시스템 인기많을것 같아 취업에 유리할 것 같은데..
사람인 회사 자체는 워라벨 별로인듯.
financial은 결제, 금융 관련된거.
인턴은 경력인지 모르겠지만 계약직은 경력이다. 이번 naver는 financial 수습직이나 경력, 프리랜서도 경력으로 처주면 가능. 인턴만 아니면 됐다.
신한은행 행원 면접에서 고객이 물류하는 고객이 왔다. 무슨 제품을 추천할거냐. 회계쪽 종류가 많은데 매출 이윤중에 뭘 선택할거고 이유는 뭐냐.
신한은행은 예외로 일반행원은 고졸도 받음. ssafy 전형도 따로 있음.
다른 교육 마치고 창업한 팀도 있다. 포스기 데이터. 금융 모델링으로 사업 아이템 잡고 한 팀이 있었다. 얘는 2개월로 더 짧았지만 창업까지 한 걸 보면 하기 나름이지 않을까. 스타트업 대단한게 일해보니까 일 다운 일을 한게 아니라 사무실, 계약서, 세금 신고 등등.. 이 빡쎘다. 진짜 할게 많다는게 저런 거 때문이다. 개발할려고 들어갔는데 전부 다해서 나왔다. 근데 커리어 쌓을려면 1년 있어야 한다. 지금은 식당 프랜차이즈랑 계약해서 상권분석, 데이터분석 등등을 해줌. GIS도 분석해줘서 쓰고 입지분석, 상권분석. 이런걸로 타게팅 잡아서 최종적으로 신용평가 모델을 하는 거라고 하더라. b2c는 고객대상, b2b 회사 상대로 상대하는거. 보통 솔루션 쪽은 b2b.
스타트업은 배우면서 일하는게 맞는 듯. 근데 면접때 말하면 안되는건 당연. 뻥튀기도 필요하지만 안들켜야 함. 실무 1타 면접때 다 알겠지. IT 면접 기본은 실습 지식이다.
WAS 랑 WEB 의 차이가 뭐에요? 왓스는 정적인 웹페이지 ~~ 어쩌구 저쩌구. 그럼 ~~ 라고 하셨는데, 그럼 … 는 어떻게 생각하시는지? 등으로 꼬리물고 들어옴.
인재개발원은 취업률로 성과 따지니까 일단 취업 시키려고 눈 낮추라고 하는거고, 초봉이 중요하다. 연봉이 낮으니까 이직이 쉽지. 이게 SI 현실. 직업훈련…
중견은 실력보다는 업무시스템에 대해. 유지 관리가 중요. 개발자로서 발전하기 힘든 면이 있고.. 안전하면 좋겠지만 개발도 힘들고 이직도 제한적.
====================
후기
일찍 자서 충분한 수면을 하자.






































