======================
학습내용
pandas II
Groupby 1
df.groupby("Team")["Points"].std()
h_index = df.groupby(["Team", "Year"])["Points"].sum()
Team Year
Devils 2014 863
2015 673
Kings 2014 741
2016 756
2017 788
Riders 2014 876
2015 789
2016 694
2017 690
Royals 2014 701
2015 804
kings 2015 812
Name: Points, dtype: int64
h_index.index
MultiIndex([('Devils', 2014),
('Devils', 2015),
( 'Kings', 2014),
( 'Kings', 2016),
( 'Kings', 2017),
('Riders', 2014),
('Riders', 2015),
('Riders', 2016),
('Riders', 2017),
('Royals', 2014),
('Royals', 2015),
( 'kings', 2015)],
names=['Team', 'Year'])
h_index["Devils":"Kings"]
Team Year
Devils 2014 863
2015 673
Kings 2014 741
2016 756
2017 788
Name: Points, dtype: int64
h_index.unstack()
Year 2014 2015 2016 2017 Team Devils 863.0 673.0 NaN NaN Kings 741.0 NaN 756.0 788.0 Riders 876.0 789.0 694.0 690.0 Royals 701.0 804.0 NaN NaN kings NaN 812.0 NaN NaN
h_index.swaplevel()
h_index.sort_index(level=1) # 레벨을 잘 지정해줘야 함
h_index.std(level=0) # 레벨을 잘 지정해줘야 함
h_index.sum(level=1) # 레벨을 잘 지정해줘야 함
Group by 2
grouped = df.groupby("Team")
for name, group in grouped:
print(name) print(group)
grouped.get_group("Devils")
grouped.agg(max)
grouped.agg(np.mean)
grouped.describe().T
grouped.transform(lambda x: x) # 하면 원래 값 나옴
score = lambda x: (x - x.mean()) / x.std()
grouped.transform(score) # 정규화 된 값 출력
df.groupby("Team").filter(lambda x: len(x) >= 3)
df.groupby("Team").filter(lambda x: x["Points"].mean() > 700)
Case study
| index | date | duration | item | month | network | network_type | |
|---|---|---|---|---|---|---|---|
| 0 | 0 | 15/10/14 06:58 | 34.429 | data | 2014-11 | data | data |
| 1 | 1 | 15/10/14 06:58 | 13.000 | call | 2014-11 | Vodafone | mobile |
| 2 | 2 | 15/10/14 14:46 | 23.000 | call | 2014-11 | Meteor | mobile |
| 3 | 3 | 15/10/14 14:48 | 4.000 | call | 2014-11 | Tesco | mobile |
| 4 | 4 | 15/10/14 17:27 | 4.000 | call | 2014-11 | Tesco | mobile |
| index | date | duration | item | month | network | network_type | |
|---|---|---|---|---|---|---|---|
| 0 | 0 | 2014-10-15 06:58:00 | 34.429 | data | 2014-11 | data | data |
| 1 | 1 | 2014-10-15 06:58:00 | 13.000 | call | 2014-11 | Vodafone | mobile |
| 2 | 2 | 2014-10-15 14:46:00 | 23.000 | call | 2014-11 | Meteor | mobile |
| 3 | 3 | 2014-10-15 14:48:00 | 4.000 | call | 2014-11 | Tesco | mobile |
| 4 | 4 | 2014-10-15 17:27:00 | 4.000 | call | 2014-11 | Tesco | mobile |




| item | call | data | sms |
|---|---|---|---|
| month | |||
| 2014-11 | 107 | 29 | 94 |
| 2014-12 | 79 | 30 | 48 |
| 2015-01 | 88 | 31 | 86 |
| 2015-02 | 67 | 31 | 39 |
| 2015-03 | 47 | 29 | 25 |

| index | date | duration | item | month | network | network_type | |
|---|---|---|---|---|---|---|---|
| 0 | 0 | 2014-10-15 06:58:00 | 34.429 | data | 2014-11 | data | data |
| 1 | 1 | 2014-10-15 06:58:00 | 13.000 | call | 2014-11 | Vodafone | mobile |
| 2 | 2 | 2014-10-15 14:46:00 | 23.000 | call | 2014-11 | Meteor | mobile |
| 3 | 3 | 2014-10-15 14:48:00 | 4.000 | call | 2014-11 | Tesco | mobile |
| 4 | 4 | 2014-10-15 17:27:00 | 4.000 | call | 2014-11 | Tesco | mobile |
| month | duration | |
|---|---|---|
| 0 | 2014-11 | 26639.441 |
| 1 | 2014-12 | 14641.870 |
| 2 | 2015-01 | 18223.299 |
| 3 | 2015-02 | 15522.299 |
| 4 | 2015-03 | 22750.441 |
| duration | network_type | date | ||
|---|---|---|---|---|
| month | item | |||
| 2014-11 | call | 25547.000 | 107 | 2014-10-15 06:58:00 |
| data | 998.441 | 29 | 2014-10-15 06:58:00 | |
| sms | 94.000 | 94 | 2014-10-16 22:18:00 | |
| 2014-12 | call | 13561.000 | 79 | 2014-11-14 17:24:00 |
| data | 1032.870 | 30 | 2014-11-13 06:58:00 | |
| sms | 48.000 | 48 | 2014-11-14 17:28:00 | |
| 2015-01 | call | 17070.000 | 88 | 2014-12-15 20:03:00 |
| data | 1067.299 | 31 | 2014-12-13 06:58:00 | |
| sms | 86.000 | 86 | 2014-12-15 19:56:00 | |
| 2015-02 | call | 14416.000 | 67 | 2015-01-15 10:36:00 |
| data | 1067.299 | 31 | 2015-01-13 06:58:00 | |
| sms | 39.000 | 39 | 2015-01-15 12:23:00 | |
| 2015-03 | call | 21727.000 | 47 | 2015-02-12 20:15:00 |
| data | 998.441 | 29 | 2015-02-13 06:58:00 | |
| sms | 25.000 | 25 | 2015-02-19 18:46:00 |
| duration | network_type | date | ||||
|---|---|---|---|---|---|---|
| min | count | min | first | nunique | ||
| month | item | |||||
| 2014-11 | call | 1.000 | 107 | 2014-10-15 06:58:00 | 2014-10-15 06:58:00 | 104 |
| data | 34.429 | 29 | 2014-10-15 06:58:00 | 2014-10-15 06:58:00 | 29 | |
| sms | 1.000 | 94 | 2014-10-16 22:18:00 | 2014-10-16 22:18:00 | 79 | |
| 2014-12 | call | 2.000 | 79 | 2014-11-14 17:24:00 | 2014-11-14 17:24:00 | 76 |
| data | 34.429 | 30 | 2014-11-13 06:58:00 | 2014-11-13 06:58:00 | 30 | |
| sms | 1.000 | 48 | 2014-11-14 17:28:00 | 2014-11-14 17:28:00 | 41 | |
| 2015-01 | call | 2.000 | 88 | 2014-12-15 20:03:00 | 2014-12-15 20:03:00 | 84 |
| data | 34.429 | 31 | 2014-12-13 06:58:00 | 2014-12-13 06:58:00 | 31 | |
| sms | 1.000 | 86 | 2014-12-15 19:56:00 | 2014-12-15 19:56:00 | 58 | |
| 2015-02 | call | 1.000 | 67 | 2015-01-15 10:36:00 | 2015-01-15 10:36:00 | 67 |
| data | 34.429 | 31 | 2015-01-13 06:58:00 | 2015-01-13 06:58:00 | 31 | |
| sms | 1.000 | 39 | 2015-01-15 12:23:00 | 2015-01-15 12:23:00 | 27 | |
| 2015-03 | call | 2.000 | 47 | 2015-02-12 20:15:00 | 2015-02-12 20:15:00 | 47 |
| data | 34.429 | 29 | 2015-02-13 06:58:00 | 2015-02-13 06:58:00 | 29 | |
| sms | 1.000 | 25 | 2015-02-19 18:46:00 | 2015-02-19 18:46:00 | 17 | |
| duration | |||
|---|---|---|---|
| min | max | mean | |
| month | |||
| 2014-11 | 1.0 | 1940.0 | 115.823657 |
| 2014-12 | 1.0 | 2120.0 | 93.260318 |
| 2015-01 | 1.0 | 1859.0 | 88.894141 |
| 2015-02 | 1.0 | 1863.0 | 113.301453 |
| 2015-03 | 1.0 | 10528.0 | 225.251891 |
| min | max | mean | |
|---|---|---|---|
| month | |||
| 2014-11 | 1.0 | 1940.0 | 115.823657 |
| 2014-12 | 1.0 | 2120.0 | 93.260318 |
| 2015-01 | 1.0 | 1859.0 | 88.894141 |
| 2015-02 | 1.0 | 1863.0 | 113.301453 |
| 2015-03 | 1.0 | 10528.0 | 225.251891 |
| min_duration | max_duration | mean_duration | |
|---|---|---|---|
| month | |||
| 2014-11 | 1.0 | 1940.0 | 115.823657 |
| 2014-12 | 1.0 | 2120.0 | 93.260318 |
| 2015-01 | 1.0 | 1859.0 | 88.894141 |
| 2015-02 | 1.0 | 1863.0 | 113.301453 |
| 2015-03 | 1.0 | 10528.0 | 225.251891 |
| duration_min | duration_max | duration_mean | |
|---|---|---|---|
| month | |||
| 2014-11 | 1.0 | 1940.0 | 115.823657 |
| 2014-12 | 1.0 | 2120.0 | 93.260318 |
| 2015-01 | 1.0 | 1859.0 | 88.894141 |
| 2015-02 | 1.0 | 1863.0 | 113.301453 |
| 2015-03 | 1.0 | 10528.0 | 225.251891 |
Pivot table Crosstab
pivot은 엑셀이 있는 거라고 함
- Index 축은 groupby와 동일함
- Column에 추가로 labeling 값을 추가하여,
- Value에 numeric type 값을 aggregation 하는 형태
| index | date | duration | item | month | network | network_type | |
|---|---|---|---|---|---|---|---|
| 0 | 0 | 2014-10-15 06:58:00 | 34.429 | data | 2014-11 | data | data |
| 1 | 1 | 2014-10-15 06:58:00 | 13.000 | call | 2014-11 | Vodafone | mobile |
| 2 | 2 | 2014-10-15 14:46:00 | 23.000 | call | 2014-11 | Meteor | mobile |
| 3 | 3 | 2014-10-15 14:48:00 | 4.000 | call | 2014-11 | Tesco | mobile |
| 4 | 4 | 2014-10-15 17:27:00 | 4.000 | call | 2014-11 | Tesco | mobile |
| duration | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| network | Meteor | Tesco | Three | Vodafone | data | landline | special | voicemail | world | |
| month | item | |||||||||
| 2014-11 | call | 1521 | 4045 | 12458 | 4316 | 0.000 | 2906 | 0 | 301 | 0 |
| data | 0 | 0 | 0 | 0 | 998.441 | 0 | 0 | 0 | 0 | |
| sms | 10 | 3 | 25 | 55 | 0.000 | 0 | 1 | 0 | 0 | |
| 2014-12 | call | 2010 | 1819 | 6316 | 1302 | 0.000 | 1424 | 0 | 690 | 0 |
| data | 0 | 0 | 0 | 0 | 1032.870 | 0 | 0 | 0 | 0 | |
| sms | 12 | 1 | 13 | 18 | 0.000 | 0 | 0 | 0 | 4 | |
| 2015-01 | call | 2207 | 2904 | 6445 | 3626 | 0.000 | 1603 | 0 | 285 | 0 |
| data | 0 | 0 | 0 | 0 | 1067.299 | 0 | 0 | 0 | 0 | |
| sms | 10 | 3 | 33 | 40 | 0.000 | 0 | 0 | 0 | 0 | |
| 2015-02 | call | 1188 | 4087 | 6279 | 1864 | 0.000 | 730 | 0 | 268 | 0 |
| data | 0 | 0 | 0 | 0 | 1067.299 | 0 | 0 | 0 | 0 | |
| sms | 1 | 2 | 11 | 23 | 0.000 | 0 | 2 | 0 | 0 | |
| 2015-03 | call | 274 | 973 | 4966 | 3513 | 0.000 | 11770 | 0 | 231 | 0 |
| data | 0 | 0 | 0 | 0 | 998.441 | 0 | 0 | 0 | 0 | |
| sms | 0 | 4 | 5 | 13 | 0.000 | 0 | 0 | 0 | 3 | |
| network | Meteor | Tesco | Three | Vodafone | data | landline | special | voicemail | world | |
|---|---|---|---|---|---|---|---|---|---|---|
| month | item | |||||||||
| 2014-11 | call | 1521.0 | 4045.0 | 12458.0 | 4316.0 | NaN | 2906.0 | NaN | 301.0 | NaN |
| data | NaN | NaN | NaN | NaN | 998.441 | NaN | NaN | NaN | NaN | |
| sms | 10.0 | 3.0 | 25.0 | 55.0 | NaN | NaN | 1.0 | NaN | NaN | |
| 2014-12 | call | 2010.0 | 1819.0 | 6316.0 | 1302.0 | NaN | 1424.0 | NaN | 690.0 | NaN |
| data | NaN | NaN | NaN | NaN | 1032.870 | NaN | NaN | NaN | NaN | |
| sms | 12.0 | 1.0 | 13.0 | 18.0 | NaN | NaN | NaN | NaN | 4.0 | |
| 2015-01 | call | 2207.0 | 2904.0 | 6445.0 | 3626.0 | NaN | 1603.0 | NaN | 285.0 | NaN |
| data | NaN | NaN | NaN | NaN | 1067.299 | NaN | NaN | NaN | NaN | |
| sms | 10.0 | 3.0 | 33.0 | 40.0 | NaN | NaN | NaN | NaN | NaN | |
| 2015-02 | call | 1188.0 | 4087.0 | 6279.0 | 1864.0 | NaN | 730.0 | NaN | 268.0 | NaN |
| data | NaN | NaN | NaN | NaN | 1067.299 | NaN | NaN | NaN | NaN | |
| sms | 1.0 | 2.0 | 11.0 | 23.0 | NaN | NaN | 2.0 | NaN | NaN | |
| 2015-03 | call | 274.0 | 973.0 | 4966.0 | 3513.0 | NaN | 11770.0 | NaN | 231.0 | NaN |
| data | NaN | NaN | NaN | NaN | 998.441 | NaN | NaN | NaN | NaN | |
| sms | NaN | 4.0 | 5.0 | 13.0 | NaN | NaN | NaN | NaN | 3.0 |
crosstab
- 특히 두 칼럼에 교차 빈도, 비율, 덧셈 등을 구할 때 사용
- Pivot table의 특수한 형태
- User-Item Rating Matrix 등을 만들 때 사용가능함
df_movie = pd.read_csv("data/movie_rating.csv") df_movie.head()
| critic | title | rating | |
|---|---|---|---|
| 0 | Jack Matthews | Lady in the Water | 3.0 |
| 1 | Jack Matthews | Snakes on a Plane | 4.0 |
| 2 | Jack Matthews | You Me and Dupree | 3.5 |
| 3 | Jack Matthews | Superman Returns | 5.0 |
| 4 | Jack Matthews | The Night Listener | 3.0 |
df_movie.pivot_table( ["rating"], index=df_movie.critic, columns=df_movie.title, aggfunc="sum", fill_value=0, )
| rating | ||||||
|---|---|---|---|---|---|---|
| title | Just My Luck | Lady in the Water | Snakes on a Plane | Superman Returns | The Night Listener | You Me and Dupree |
| critic | ||||||
| Claudia Puig | 3.0 | 0.0 | 3.5 | 4.0 | 4.5 | 2.5 |
| Gene Seymour | 1.5 | 3.0 | 3.5 | 5.0 | 3.0 | 3.5 |
| Jack Matthews | 0.0 | 3.0 | 4.0 | 5.0 | 3.0 | 3.5 |
| Lisa Rose | 3.0 | 2.5 | 3.5 | 3.5 | 3.0 | 2.5 |
| Mick LaSalle | 2.0 | 3.0 | 4.0 | 3.0 | 3.0 | 2.0 |
| Toby | 0.0 | 0.0 | 4.5 | 4.0 | 0.0 | 1.0 |
pd.crosstab( index=df_movie.critic, columns=df_movie.title, values=df_movie.rating, aggfunc="first", ).fillna(0)
| title | Just My Luck | Lady in the Water | Snakes on a Plane | Superman Returns | The Night Listener | You Me and Dupree |
|---|---|---|---|---|---|---|
| critic | ||||||
| Claudia Puig | 3.0 | 0.0 | 3.5 | 4.0 | 4.5 | 2.5 |
| Gene Seymour | 1.5 | 3.0 | 3.5 | 5.0 | 3.0 | 3.5 |
| Jack Matthews | 0.0 | 3.0 | 4.0 | 5.0 | 3.0 | 3.5 |
| Lisa Rose | 3.0 | 2.5 | 3.5 | 3.5 | 3.0 | 2.5 |
| Mick LaSalle | 2.0 | 3.0 | 4.0 | 3.0 | 3.0 | 2.0 |
| Toby | 0.0 | 0.0 | 4.5 | 4.0 | 0.0 | 1.0 |
df_movie.groupby(["critic", "title"]).agg({"rating": "first"})
| rating | ||
|---|---|---|
| critic | title | |
| Claudia Puig | Just My Luck | 3.0 |
| Snakes on a Plane | 3.5 | |
| Superman Returns | 4.0 | |
| The Night Listener | 4.5 | |
| You Me and Dupree | 2.5 | |
| Gene Seymour | Just My Luck | 1.5 |
| Lady in the Water | 3.0 | |
| Snakes on a Plane | 3.5 | |
| Superman Returns | 5.0 | |
| The Night Listener | 3.0 | |
| You Me and Dupree | 3.5 | |
| Jack Matthews | Lady in the Water | 3.0 |
| Snakes on a Plane | 4.0 | |
| Superman Returns | 5.0 | |
| The Night Listener | 3.0 | |
| You Me and Dupree | 3.5 | |
| Lisa Rose | Just My Luck | 3.0 |
| Lady in the Water | 2.5 | |
| Snakes on a Plane | 3.5 | |
| Superman Returns | 3.5 | |
| The Night Listener | 3.0 | |
| You Me and Dupree | 2.5 | |
| Mick LaSalle | Just My Luck | 2.0 |
| Lady in the Water | 3.0 | |
| Snakes on a Plane | 4.0 | |
| Superman Returns | 3.0 | |
| The Night Listener | 3.0 | |
| You Me and Dupree | 2.0 | |
| Toby | Snakes on a Plane | 4.5 |
| Superman Returns | 4.0 | |
| You Me and Dupree | 1.0 |
Merge & Concat
merge
- SQL에서 많이 사용하는 Merge와 같은 기능
- 두 개의 데이터를 하나로 합침

pd.merge(df_a, df_b, on="subject_id")
pd.merge(df_a, df_b, left_on="subject_id", right_on="subject_id") # 다른 이름끼리 묶음
pd.merge(df_a, df_b, on="subject_id", how="left")
pd.merge(df_a, df_b, on="subject_id", how="right")
pd.merge(df_a, df_b, on="subject_id", how="outer")
pd.merge(df_a, df_b, on="subject_id", how="inner") # inner가 default
pd.merge(df_a, df_b, right_index=True, left_index=True) # 두 df의 index가 모두 살아있음
df_new = pd.concat([df_a, df_b])
df_new.reset_index()
df_a.append(df_b)
밑으로 이어붙임
df_new = pd.concat([df_a, df_b], axis=1) df_new.reset_index()
옆으로 이어붙임persistence
Database connection
- Data loading시 db connection 기능을 제공함
그냥 .db 파일 불러와서 sql문 쓰는거다
import sqlite3 # pymysql 설치
하고싶은거 한 다음에 pd로 dataframe으로.. 아직은 가능하다 정도만
conn = sqlite3.connect("./data/flights.db") cur = conn.cursor() cur.execute("select * from airlines limit 5;") results = cur.fetchall()
df_airplines = pd.read_sql_query("select * from airlines;", conn)
df_airports = pd.read_sql_query("select * from airports;", conn)
df_routes = pd.read_sql_query("select * from routes;", conn)
XLS persistence
- Dataframe의 엑셀 추출 코드
- Xls 엔진으로 openpyxls 또는 XlsxWrite 사용
엑셀파일로도 쓸 수 있다.
conda install openpyxl 이나 conda install XlsxWriter 깔아야함
writer = pd.ExcelWriter("./data/df_routes.xlsx", engine="xlsxwriter") df_routes.to_excel(writer, sheet_name="Sheet1")
df_routes.to_pickle("./data/df_routes.pickle")
df_routes_pickle = pd.read_pickle("./data/df_routes.pickle") df_routes_pickle.head()
df_routes_pickle.describe()
확률론 맛보기
딥러닝의 기본 바탕이되는 확률론에 대해 소개합니다.
확률분포, 조건부확률, 기대값의 개념과 몬테카를로 샘플링 방법을 설명합니다.
데이터의 초상화로써 확률분포가 가지는 의미와 이에 따라 분류될 수 있는 이산확률변수, 연속확률변수의 차이점에 대해 설명합니다.
확률변수, 조건부확률, 기대값 등은 확률론의 매우 기초적인 내용이며 이를 정확히 이해하셔야 바로 다음 강의에서 배우실 통계학으로 이어질 수 있습니다. 기대값을 계산하는 방법, 특히 확률분포를 모를 때 몬테카를로 방법을 통해 기댓값을 계산하는 방법 등은 머신러닝에서 매우 빈번하게 사용되므로 충분히 공부하시고 넘어가시기 바랍니다.
에측이란 것은 예측의 오차의 분산을 최소화하는 목적 이다.
왜 필요한가
- 딜버닝은 확률론 기반의 기계학습 이론에 바탕을 두고 있다.
- 기계학습에서 사용되는 손실함수(loss function)들의 작동 원리는 데이터 공간을 통계적으로 해석해서 유도하게된다
- 회귀 분석에서 손실함수로 사용되는 L2-노름은 예측오차의 분산을 가장 최소화하는 방향으로 학습하도록 유도한다
- 분류 문제에서 사용되는 교차엔트로피(cross-entropy)는 모델 예측의 불확실성을 최소화하는 방향으로 학습하도록 유도한다
- 분산 및 불확실성을 최소화하기 위해서는 측정하는 방법을 알아야 한다
데이터는 확률변수로 (x,y) ~ D 라 표기
확률변수는 확률분포 D에 따라 이산형(discrete)과 연속형(continuous) 확률변수로 구분하게 된다. 시그마랑 적분으로 나뉜다고




조건부확률분포 P(X|y) 는 데이터 공간에서 입력 X와 출력 y 사이의 관계를 모델링합니다.
조건부확률로 안다는게 y가 1인 경우는 x가 어디 부근일때더라, x가 2이상인 경우엔 y=2가 많다더라~ 라는 식으로 안다는 거고. 저건 여러 데이터들을 discrete로 접근할 수 있다는 걸 알려주는 듯. 저렇게 크기를 정의해 놔야 분석을 하든 뭘 하든 할 수 있으니. 전 시간에 배웠던 거에선 저 데이터 다 계산해서 행렬로 푼 방법들 연립방적식이나 선형회귀분석으로 풀거나 경사하강법을 그것도 일부만 빼내서 확률적 경사하강법을 쓰던지 할 텐데, 조건부 확률을 사용하는 식으로 확률적으로 접근해서 풀기도 한다. 결국 모두 목적은 입력값 X와 출력값 y 사이의 관계를 모델링 한다. 즉 weight를 알아낸다고.

자꾸 회귀회귀 하는데 회귀가 뭔뜻이야 => https://brunch.co.kr/@gimmesilver/17
조건부확률분포 P(X|y) 는 입력변수 x가 주어졌을때 정답인 확률 y를 의미.
분류문제에서 softmax(Wpi + b)는 데이터 x로부터 추출된 특징패턴 pi(x)와 가중치행렬 W를 통해 조건부확률 P(y|X)를 계산한다. 즉 내가 구하고 싶은게 P(y|X) 이고 분류문제에선 softmax(Wpi + b) 를 이용해서 구할 수 있다는걸 뜻하는것 같다.
회귀 문제의 경우 보통 연속확률분포라 확률밀도함수로 조건부기대값 E[y|X] 을 추정한다. 근데 왜 쓰냐. 조건부기대값은 L2를 최소화하는 함수와 일치하더라. 걍 수학적으로 증명돼있다. 예측의 오차의 분산을 최소화하는 목적에 적절함.

기대값 뭔지 알지? 이걸 이용해 분산, 첨도, 공분산등 여러 통계량 계산 가능 그래서 기대값은 굉장히 중요한 통계량이면서 도구다.



딥러닝은 다층신경망(MLP)을 이용하여 데이터로부터 특징패턴 pi를 추출한 후에 조건부확률을 계산하거나 조건부기대값을 추정하는 식으로 학습을 하게된다.
그래서 특징패턴을 학습하기 위해서 목적으로 주어진 손실함수를 사용할 지에 대해서는 기계학습의 문제와 모델에 의해 결정된다.
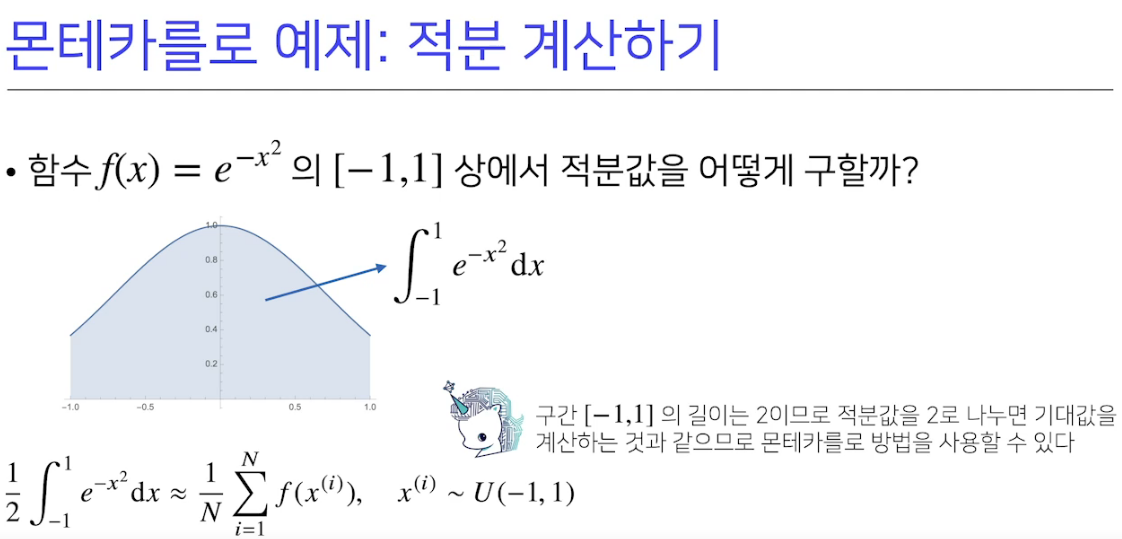
기계학습은 명시적으로 확률분포를 모를때가 많다. 그래서 몬테카를로 샘플링 방식으로 데이터를 이용해서 우회적으로 계산한다. 반복적으로 구하면 분산도 구할 수 있어서 오차범위도 계산 가능하다. 근데 데이터로 추정하는거라 수가 너무 적거나 하면 오차범위가 너무 넓어짐..
======================
퀴즈
연속형 확률변수의 한 지점에서의 밀도 (density) 는 그 자체로 확률값을 가진다. 아님. 회귀 문제의 경우 조건부기대값으로 추정하는듯. 주어진 함수에다가 확률밀도함수를 곱해서 적분. 해서 구한게 조건부기대값
======================
피어세션
소프트맥스 이름의 유래. 하드하게 나누는게 아닌 부드럽게..
다 손으로 6 쓰는게 다르니까 이것이 6일 확률이 높다.
소프트맥스 e쓰는 이유. 미분이 편리. 무리수다보니 하드한 값이 안나오고 소프트한 값이 나옴. 확률적인 값을 통해 확장된 모델에서 분류가 된다.
학습할 땐 당연히 써야한다. 원래 확률이 아닌데 확률처럼 쓴다. 그래서 분류하기에 적절해서 소프트맥스에 쓰기에 적절하고 사용한다. 0.9가 나왔다고 0.9% 가 아니고
logistic function이 어떻게 나오는지. activate function을 어떤걸 쓰는건지.
vanishing gradient. sigmoid들 이해하고 보면 수식 이해하는데 간단해짐
sigmoid단점. 매우크면 1, 매우 작으면 0에 가까워져서 학습에 힘들어서 잘 안써짐. 그래서 reLU 나 riky reLU를 쓴다. 중간에 relu써도 마지막은 구별만 하면 되니까 logistic을 써도 상관없겠다.
선형모델. 비선형모델. 선형모델은 xor 분류 불가능. 비선형으로 바꿔야함. 가능하게 하는게 활성함수. sigmoid, tanh, reLU. 학습 속도가 reLU에 비해 많이 떨어져서 reLU쓴다. 반복이 되서 층층이 쌓이면 mlp. 역전파는 반복해서 들어가야 하는데 각 노드마다 tensor를 저장해야함. 그래서 메모리를 많이 잡아먹는다. 각 연산 결과를 메모리에 일일이 저장해야 해서. 레이어마다 입력값을 메모리에 저장해야 된다.
왜 층이 깊어질수록 파라미터가 적어서 효율적인게 가능하다. 근데 모델 학습에 어렵다. 안깊으면 넓어서 힘들다. 연쇄학습에 필요한게 역전파 알고리즘이다.
생각해야겠다 신경쓴게 층이 깊어질수록 정말 효율적인 건가 고려해야 할 것 같음. 깊게 안하고 얇게 하려면 깊게 안한 만큼 더 엄청 많이 학습해야하는것 같음.
비선형끼리 합쳐서 선형처럼 만든다는게 신기했음.
NH계열 초봉 5000. 직급 5~6급. 농협 최고다. 카카오 엔터프라이즈. 일하기가 굉장해 좋다. 자유롭고 AI담당. 브레인. 엔터프라이즈. 주로 기업용 솔루션. 카카오워크. 카카오aws
=======================
후기
설명이 좀 어려운것 같다. ppt에다 이해를 위한 개념을 적어주셨으면 좋겠다. 아니면 내가 새벌식 타자를 익히고 말 다 적어서 요약하는 것도 좋을 것 같다.
피어세션보니 다들 정말 깊게 파고들며 공부하는 것 같다. 나도 남들이 하는 질문 보면서 탐구해보는 시간이 필요한 것 같다.
댓글 없음:
댓글 쓰기