https://www.notion.so/8148e6242b7344a1837c92d5d7d2724a?v=944e8b68bc3143fe878ae74e0b7d9281
2021년 4월 11일 일요일
2021년 4월 7일 수요일
AITech P-stage1 [Day 8] 앙상블 실패, f1loss로 학습해보는중
===================================
목표
어제 못했던 앙상블 해보기
==================================
행동
어제 mask, gender, age 각각의 모델에 대한 학습을 다 하고, 각 모델에 eval data 를 통과시켜 나온 결과를 합쳐 최종 결과를 내는 걸 만들었다. 결과는 실망스러웠다. 단일 모델로 했을 때보다 결과가 안 나왔기 때문이다.
age는 원래 딱 60살만 2 label을 가지지만 59살 이상을 2label로 가지게 했을 때 결과가 잘 나왔다. 또 epoch를 많이 돌리고 val loss와 val acc에 변화가 없어서 overfitting이라고 생각했지만 내가 overfitting이라고 생각한 checkpoint를 넣고 돌리면 결과가 더 잘 나왔다. 즉 학습을 엄청 많이 하는게 장땡인 것이다. 이거 말고 평소에 다른거 할 땐 언제나 overfitting이 일어나서 좀 낮은 epoch를 했어야 했는데 의외였다.
그래서 learning rate 도 처음부터 1e-5로 시작하고 lr이 줄어드는 step 조건도 줄이면서 진짜 진짜 val과 train에 변화가 없을 때 끝내고 있다. 또 loss가 acc이 목적이 아니라 f1 loss가 목적이 되었다는 것을 생각하며 모든 모델을 f1 loss로 학습시키고 있다. 어떻게 될 지는 잘 모르겠다.
==================================
회고
처음부터 앙상블로 시작했으면 작업시간이 줄어들었을 것 같긴 하다. 그래도 처음이라 notebook으로 작성한걸 py로 바꾸고, 단일 모델로 된걸 앙상블로 바꾸고 그 와중에 GPU memory out같은 오류 등을 겪었다. 이제 인지했고 이게 어떻게 보면 baseline code를 만드는 과정이었으니까 다음에 할 땐 괜찮아 질지도 모르겠다.
2021년 4월 6일 화요일
AITech P-stage1 [Day 7] 단일 모델 실험 끝, 앙상블 실험중..
=======================
피어세션
나이를 제일 빡센(깊은) layer. resnetnext 같은거
adamw
crossentropy에도 weight를 줄 수가 있다.
================================
마스터세션
vscode 방법들.
tumx. 꺼지더라도 실행하는 거인듯. 꼭 알아야 겠다.
dracula theme
image-tile-viewer
잘 안되면 reload
pytorch snippets. pytorch 코드 그냥 만들어주네
extract method. refactoring이 쉽다.
device checking.. train도 그냥 만들어주고..
디버깅 서버
jedi, pylance.
jedi는 느리다. pylance빠르다.
근데 pylance는 자동완성 못찾아서 사용하기 힘듬.
보통 pip install 보면 jedi 설치되어 있음.
디버깅시 justMyCode. 디버깅까지 빠른데 라이브러리 까지 못들어감. 종단점을 걸어도 안들어감. justmycode를 false로 하면 라이브러리 까지 들어감. 이래야 에러가 나타나게 된 data input type을 볼 수 있음. 어디서 에러가 났는지 확인 가능.
pytorch template. configuration file로 주는것도 가능.
power mode
================================
목표
어제 못끝낸 IDLE 끝내서 일단 단일모델 vgg19 하도록 만들기, efficientnet 해보기, 앙상블 해보기
================================
행동
일단 단일 모델로 돌리는 코드는 만드는데 성공했다. 모델도 클래스만 바꾸고 나머진 건드리지 않아도 동작하고, 저장한 모델을 불러오는데 불러올 때 어떤 모델을 사용해서 학습한건지 json에 들어있는 정보를 통해 알맞은 모델을 자동으로 불러온다. 또 단순히 저장된 모델을 불러오는게 아니라 몇번째 시도에서 몇번째 epoch로 저장된 checkpoint를 단순히 args 를 통해 설정할 수 있다. 내가 봐도 정말 잘 만들었다.
근데 문제는 앙상블이다. 단일모델용으로 만든 train 코드를 복사 붙여넣기로 만들긴 했지만 현재 GPU 메모리 초과 문제에 닥쳐있다. 각각 따로 학습시키거나 GPU를 매번 초기화하는 함수가 있나 등을 살펴봐야겠다.
==========================
회고
늦게 일어났다. 늦게 자서 그렇다.
GPU 메모리 문제에 닥칠 줄은 몰랐다. 코드에만 신경써서 그런 것 같다. 그래도 대략적인 틀은 짜놨으니 약간 안심한다. 그래도 내일모래가 끝이다. 사실상 내일이 끝이라고 생각해야 할 듯.
단일모델로는
15 sub_EfficientNet_b4_21y04m06d09_03_55_0.03_0.97_40.csv 76.7302% 0.7067
로 이게 최대인것 같다.
2021년 4월 5일 월요일
AITech P-stage1 [Day 6] 데이터 시각화, 아직 python IDLE로 만드는 중..
==============================
수업내용
시각화를 진행할 데이터
1. 데이터셋 관점 (global)
2. 개별 데이터의 관점 (local)
정형데이터는 평소에 보던 csv, tsv. item, attribute, cell.
통계적 특성과 feature 사이 관계, 데이터 간 관계, 데이터 간 비교.
시계열데이터는 시간 흐름에 따른 데이터.
기온, 주가등의 정형데이터와 음성, 비디오 같은 비정형 데이터 존재.
시간 흐름에 따른 추세(Trend), 계절설(Seasonality), 주기성(Cycle) 등을 살핌.
지리/지도 제이터
거리, 경로, 분포등.
관계 데이터
Graph visualization / Network Visualization
객체는 Node로, 관계는 Link로
계층적 데이터
포함관계가 분명한 데이터
Tree, Treemap, Sunburst
수치적 데이터
수치형(numerical) 안에 연속형(continuous), 이산형(discrete)
범주형(categorical) 안에 명목형(norminal), 순서형(ordinal)
마크와 채널 (mark and channel)
딱히 주의를 주지 않아도 구분할 수 있는 특징. 시각적 분리 (visual popout)
실습
https://colab.research.google.com/drive/1DWqDZPUnuMWQwyBleYk6vvKW_W7p3c5h?usp=sharing
정말 정말 정말 정말 좋다. 기본에 충실한 plt.
================================
피어세션
oversampling
val을 다 일정비율로 맞춰서.
ffhq 사람얼굴 데이터셋, 쓸수있는거 900개.
efficientnet이 짱. resnet18 보다도.
==================================
목표
주말에 IDLE 만들던거 다 만들기
=========================
행동
예시코드로 준거는 거의 다 구현했는데 그 이후에 문제다. 모델 훈련한거 불러와서 csv로 저장하는거.
======================
회고
코딩에 생각보다 시간이 너무 오래 걸린다.
나도 15시간 공부 해보기를 해야되나..
2021년 4월 2일 금요일
AITech P-stage1 [Day 5]
====================================
학습내용

voting으로 앙상블을 할 수도 있는데 여기서도 hard, soft를 사용할 수 있다.

K-fold

원래 멀쩡한 데이터가 있다면 그걸 data augmentation 할 수 있잖아? 그럼 data generator로 나온 결과도 같은 답이어야 함. 그래서 각각의 데이터들끼리 soft 결과 합을 해서 가장 일반적인 결과를 내놓는 방식으로 학습할 수도 있다.
물론 앙상블을 하는 모델 갯수만큼 학습 시간도 많이 늘어남.



https://optuna.org/#code_examples
파라미터도 학습으로 결정할 수 있게 만들수는 있지만 뭐가 좋은지 돌려보고 때려박아서 결정하는거라 정말 시간이 많이 걸린다. 저 optuna library는 뭐라는지 모르겠음.
디버깅 방법..
tensorboard, wandb.
tensorboard로 평소처럼 각 epoch에 대한 train loss, acc, ... 하는것도 볼 수 있고 어떤 입력 이미지에 어떤 결과를 내는지 등등도 볼 수 있다.
wandb는 딥러닝의 깃허브 같은 거라고 하는데 ipynb에서 바로 페이지에서 확인되고 파일로 저장하고 하니까 원격으로 할때 더 편하다는것 같다.
notebook? ide?
notebook은 그때그때 볼 때, 특히 EDA할때 편리. 한번 데이터를 불러놓고 이것저것 해보면서 볼 수 있으니까. 하지만 매번 그 많은 함수들을 복붙해야 함.
ide는 좀 번거롭긴 하지만 한번 .py로 저장해놓으면 불러오면서 사용 가능. 또 터미널에서 config.json이나 --arg 같은걸로 입력해줘서 바로 실행가능하게끔 만들 수 있으니까 구축해놓은 뒤 여러가지 실험을 해볼 때 편리.
kaggle등에서 다른사람이 한걸 볼땐 코드를 봐서 원리를 아는것도 중요하지만 왜 그 사람이 그런 코드를 무슨 생각으로 짰는지 설명을 보면 알 수 있다. 설명을 보고 그 사람의 발상 등을 알아내는게 큰 도움이 되는 듯.
최신논문과 그에따른 코드들을 paper에서 확인 가능.
또 공유하는 것을 주저하지 말것. 모르는거도 알 수 있고 내가 맞는지 확인도 가능하고 등 여러 이점이 많음.
==============================
피어세션
# DynamicBalanceSampler
train_x , val_x , train_y , val_y = train_test_split(df , df['label'] , test_size=0.3, shuffle = True )
train_dataset = CustomDataset(img_path , train_x , train_transforms)
val_dataset = CustomDataset(img_path , val_x , val_transforms)
sampler = data_catal.DynamicBalanceSampler(labels=train_dataset.get_labels())
train_loader = torch.utils.data.DataLoader(train_dataset,sampler=sampler, batch_size= batch_size , num_workers = num_workers)
val_loader = torch.utils.data.DataLoader(val_dataset, batch_size = batch_size , shuffle = False , num_workers = num_workers )
get_labels : 모든 label 가져오기
=========================
목표
vgg19말고 resnet32, efficientnet 같은걸로 사용해보기, 앙상블 해보기
ide 환경으로 만들기. cell이 너무 많아지니 힘들다.
=========================
행동
놀기만함...
========================
회고
시간을 꾸준히 많이 투자하자.
2021년 4월 1일 목요일
AITech P-stage1 [Day 4] data imbalance..
=====================================
수업내용

loss 도 사실 nn.Module 클래스. 그래서 layer처럼 되는거고, 자기가 원하는 식으로 만들 수도 있다. loss.backward()를 하면 require_grad=True 인 것들에 대해 loss layer에서 부터의 변화량 만큼 학습시키는 거임.

근데 loss도 그냥 loss를 하는것 보다는 여러 상황을 고려해서 하는게 더 낫더라. 해서 나온 여러 loss 방법들. 식을 잘 정의하면 고려할 수 있나보다.


optimizer는 이 loss로 구한 error만큼 움직이긴 할 건데 어떻게 움직일거냐 하는걸 결정함.
학습중에 learning rate를 감소시킬 순 없을까? 해서 나온것들이 몇개 있음.
https://www.kaggle.com/isbhargav/guide-to-pytorch-learning-rate-scheduling/log

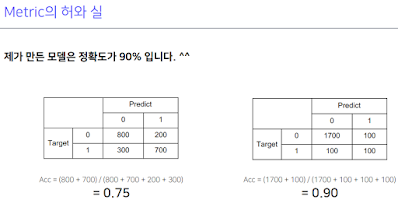

Metric은 실제 모델을 deploy할 때 성능평가.
모델 훈련시킬 때 model.train() 해서 안에 들어있는 dropout과 batchnorm을 활성화 시킨다고 해놓고 훈련한다.
이제 훈련시킬 때 사용하는 optimizer.zero_grad(), criterion, optimizer.step()을 보자.

zero_grad는 각 파라미터 안에 전에 미분했던 값이 들어있을 텐데 그걸 초기화 시켜주는 것. 이걸 안하면 돌았을 때 전에 들어있던 미분값이랑 새로 나온 미분값이랑 더해진다. 이걸 이용할 수도 있다.


loss도 chain에 넣어줌으로써 각 layer parameter에 대한 loss layer의 미분값을 구할 수 있는 것.


step() 을 사용해서 이렇게 저장된 미분값들을 반영해줘서 update. 업데이트 방법은 optimizer에서 정의하니까 optimizer.step() 이다.
이렇게 과정을 알았으면 응용도 가능하다.

각 batch마다 학습시키는게 아니라 2번씩 쌓아서 학습시키는거.
이렇게 학습시키면 테스트하는 eval 과정도 거쳐야 하는데, model.eval()로 하거나 매번 하는게 불편하면 with torch.no_grad()로 하면 된다.

이게 검증이지.

모델 저장하는건 그냥 하면 된다. 결과를 csv에 넣어서 제출하는것도..

이 모든게 힘들고 귀찮으니까 keras처럼 간단하게 만드는 pytorch lightning이라는 프로젝트가 진행중이지만 내부를 알아야 활용이 되니까.
======================
피어세션
resnet 78% 나옴
valid를 사람 별로 나눠보자
efficient net d1 72%
모델을 나눠서 해보기?
optimizer에서 papers의 madgrad
def seed_everything(seed: int = 42):
random.seed(seed)
np.random.seed(seed)
os.environ["PYTHONHASHSEED"] = str(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed) # type: ignore
torch.backends.cudnn.deterministic = True # type: ignore
torch.backends.cudnn.benchmark = True
===============================
목표
가끔 학습이 잘 안되고 valid data에 대한 accuracy가 0으로 나오는 이유 분석하기, 해결법 찾기, 각 클래스에 대한 모델을 따로 만들어 앙상블 해보기
=============================
행동
일단 0으로 나오는 이유는 코드가 문제가 아니라 데이터 양이 imbalance해서 그런 것이라는걸 알아냈다. 즉 label 4가 제일 많아서 4로 overfitting 훈련된다.
그래서 문제는 데이터 불균형이고 이를 해결하는 방법이 Focal loss라고 한다. 그래서 지금 https://catalyst-team.github.io/catalyst/_modules/catalyst/contrib/nn/criterion/focal.html#FocalLossMultiClass 여기서 돌리고 있는데 잘 되는 것 같다. 문제는 코드를 봐도 원리를 모르겠어서 좀 더 뜯어봐야 할듯. 원래는 catalyst 의 Focal loss말고 balanceclasssampler랑 dynamicbalanceclasssampler 를 보고 이름과 설명 단어좀 보면 데이터 불균형을 알아서 잘 분배해서 학습시키는게 가능하게 하는 걸까? 해서 여러가지 해봤는데 사용법을 아직도 잘 모르겠다. 일단 balanceclassampler는 임의의 list를 넣으면 되는거라 사용하기 쉬울 것 같은데 dynamicbalanceclasssampler는 넣기도 좀 복잡하고 잠깐 해봤는데도 내가 생각한대로 행동을 안해서 좀 더 사용법을 찾아보거나 해야 할듯. 예시도 안나온단 말이야.
그리고 앙상블 이런건 딴짓하느라 못했다.
처음 움직이는 방향으로 결정이 너무 크게 나니 lr를 0.0001로 했더니 어느정도 되는 것 같다. random seed도 이제 설정할 수 있게 해놨다.
=============================
회고
딴짓을 많이 하는 것 같다. 그래도 앙상블 이런거 얘기 들어보면 정말 다양한 시도와 창의력이 필요한 것 같다. 할거랑 시도해볼게 많다는 뜻. 심지어 데이터를 만드는 것도 있으니..
피드 구독하기:
덧글 (Atom)