=====================================
수업내용

loss 도 사실 nn.Module 클래스. 그래서 layer처럼 되는거고, 자기가 원하는 식으로 만들 수도 있다. loss.backward()를 하면 require_grad=True 인 것들에 대해 loss layer에서 부터의 변화량 만큼 학습시키는 거임.

근데 loss도 그냥 loss를 하는것 보다는 여러 상황을 고려해서 하는게 더 낫더라. 해서 나온 여러 loss 방법들. 식을 잘 정의하면 고려할 수 있나보다.


optimizer는 이 loss로 구한 error만큼 움직이긴 할 건데 어떻게 움직일거냐 하는걸 결정함.
학습중에 learning rate를 감소시킬 순 없을까? 해서 나온것들이 몇개 있음.
https://www.kaggle.com/isbhargav/guide-to-pytorch-learning-rate-scheduling/log

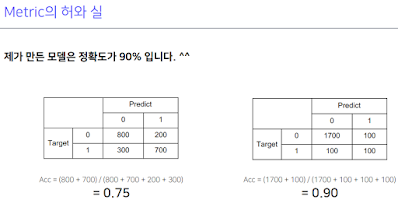

Metric은 실제 모델을 deploy할 때 성능평가.
모델 훈련시킬 때 model.train() 해서 안에 들어있는 dropout과 batchnorm을 활성화 시킨다고 해놓고 훈련한다.
이제 훈련시킬 때 사용하는 optimizer.zero_grad(), criterion, optimizer.step()을 보자.

zero_grad는 각 파라미터 안에 전에 미분했던 값이 들어있을 텐데 그걸 초기화 시켜주는 것. 이걸 안하면 돌았을 때 전에 들어있던 미분값이랑 새로 나온 미분값이랑 더해진다. 이걸 이용할 수도 있다.


loss도 chain에 넣어줌으로써 각 layer parameter에 대한 loss layer의 미분값을 구할 수 있는 것.


step() 을 사용해서 이렇게 저장된 미분값들을 반영해줘서 update. 업데이트 방법은 optimizer에서 정의하니까 optimizer.step() 이다.
이렇게 과정을 알았으면 응용도 가능하다.

각 batch마다 학습시키는게 아니라 2번씩 쌓아서 학습시키는거.
이렇게 학습시키면 테스트하는 eval 과정도 거쳐야 하는데, model.eval()로 하거나 매번 하는게 불편하면 with torch.no_grad()로 하면 된다.

이게 검증이지.

모델 저장하는건 그냥 하면 된다. 결과를 csv에 넣어서 제출하는것도..

이 모든게 힘들고 귀찮으니까 keras처럼 간단하게 만드는 pytorch lightning이라는 프로젝트가 진행중이지만 내부를 알아야 활용이 되니까.
======================
피어세션
resnet 78% 나옴
valid를 사람 별로 나눠보자
efficient net d1 72%
모델을 나눠서 해보기?
optimizer에서 papers의 madgrad
def seed_everything(seed: int = 42):
random.seed(seed)
np.random.seed(seed)
os.environ["PYTHONHASHSEED"] = str(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed) # type: ignore
torch.backends.cudnn.deterministic = True # type: ignore
torch.backends.cudnn.benchmark = True
===============================
목표
가끔 학습이 잘 안되고 valid data에 대한 accuracy가 0으로 나오는 이유 분석하기, 해결법 찾기, 각 클래스에 대한 모델을 따로 만들어 앙상블 해보기
=============================
행동
일단 0으로 나오는 이유는 코드가 문제가 아니라 데이터 양이 imbalance해서 그런 것이라는걸 알아냈다. 즉 label 4가 제일 많아서 4로 overfitting 훈련된다.
그래서 문제는 데이터 불균형이고 이를 해결하는 방법이 Focal loss라고 한다. 그래서 지금 https://catalyst-team.github.io/catalyst/_modules/catalyst/contrib/nn/criterion/focal.html#FocalLossMultiClass 여기서 돌리고 있는데 잘 되는 것 같다. 문제는 코드를 봐도 원리를 모르겠어서 좀 더 뜯어봐야 할듯. 원래는 catalyst 의 Focal loss말고 balanceclasssampler랑 dynamicbalanceclasssampler 를 보고 이름과 설명 단어좀 보면 데이터 불균형을 알아서 잘 분배해서 학습시키는게 가능하게 하는 걸까? 해서 여러가지 해봤는데 사용법을 아직도 잘 모르겠다. 일단 balanceclassampler는 임의의 list를 넣으면 되는거라 사용하기 쉬울 것 같은데 dynamicbalanceclasssampler는 넣기도 좀 복잡하고 잠깐 해봤는데도 내가 생각한대로 행동을 안해서 좀 더 사용법을 찾아보거나 해야 할듯. 예시도 안나온단 말이야.
그리고 앙상블 이런건 딴짓하느라 못했다.
처음 움직이는 방향으로 결정이 너무 크게 나니 lr를 0.0001로 했더니 어느정도 되는 것 같다. random seed도 이제 설정할 수 있게 해놨다.
=============================
회고
딴짓을 많이 하는 것 같다. 그래도 앙상블 이런거 얘기 들어보면 정말 다양한 시도와 창의력이 필요한 것 같다. 할거랑 시도해볼게 많다는 뜻. 심지어 데이터를 만드는 것도 있으니..
댓글 없음:
댓글 쓰기