===========================
학습내용
(5강) Object detection
1. object detection 이란?
물체 감지하기..
(Pclass, Xmin, Ymin, Xmax, Ymax) 같은 형태로 물체 감지.
2. Two-stage detector
two-stage가 뭐냐면 물체 위치 감지용 작업 하나, 그 물체의 class 구분 하나 해서 총 2단계로 나눠서 그렇다.
 |
| [Girshicketal.,CVPR2014] |
RCNN. 물체 위치를 뽑아내고 그 물체 위치를 다시 입력으로 넣어 class를 구분한다.
근데 이럼 매우 느릴수 밖에 없는데 위치를 뽑아낸 모든 부분에 대해 class 구분을 각각 수행해야 하기 때문에 매우 느리다. 또 단점이 region proposals는 사람의 손으로 작성한 별도의 알고리즘(selective search)으로 작성함. 그래서 학습을 통한 성능개선에 한계가 있다고 판단해서 일단 개선하고자 나온게 Fast-RCNN

Fast-RCNN은 CNN으로 뽑아놓은 feature를 그대로 활용해서 구분할 수 있도록 만들고, 물체 위치(bbox) 찾는것도 regression으로 학습가능하도록 만들어 학습시키는 것 같다. 그래서 더 빨리 나왔다.

Faster-RCNN은 기존에 있던 이론인 IoU를 채택해서 물체의 위치를 빠르게 찾게 하는 것 같다.



IoU는 몇가지의 박스들 후보, k개의 anchor boxes를 미리 정의해놓고, sliding window로 각각 위치마다 k개 후보 박스들을 넣어서 비교한다. 어느 점수 이상이 되는 것들만 남겨놓고 나머진 지우는 방식으로 한다.

그러면 box들이 겹쳐지는데 이것도 기존의 방법론으로 없애는듯. 그걸 반복하다 보면 제일 정확한게 나온다.

2. Single-stage detector

one-stage와 two-stage의 차이점. two-stage는 물체 위치 찾아내고 그 위치 box에 대해서만 classification을 쓰는데 이렇게 2단계로 나누니까 성능이 떨어진다. 그냥 일정한 위치에 대해서 다 수행해서 한번에 하자는게 one-stage

그래서 한번에 한다. k anchor box와 비슷한 접근.

저렇게 cnn 후반부 부분에 7*7 * 1024 가 나오는데 위에선 k anchor box를 2개로 정하고 수행해서 마지막 channel이 30이 나온다.
정확도는 떨어지지만 속도는 향상되었다.
 |
| [Liuetal.,ECCV2016] |

그래서 물체 크기 고려할 때 CNN이랑 poolling 하면서 어차피 크기가 줄어드니까 각각에 대해 고려하는 방식으로 해봄.
이렇게 하니까 정확도도 속도도 잘 나오더라.
4. Two-stage detector vs one-stage detector
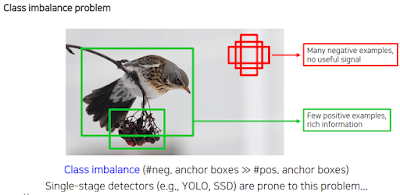
하지만 one-stage detector에도 문제가 있죠? 별 의미없는 배경에 대해서도 학습을 진행함..

그래서 일반적인 cross entropy에 감마를 덧붙인 Focal loss를 정의한다. 이렇게 하면 정답인 부분에 대해선 둔감하게 반응하고, 정답이 아닌 부분에 대해선 빠르게 변한다. loss가 작을수록 정답이긴 해서 감마가 커질수록 빈공간이 정답이 된다고 판단할 수도 있지만, gradient는 기울기로 loss의 기울기로 학습하기 때문에 가능한 일.

또다른 one-stage detector로는 RetinaNet이 있는데 전날에 했던 U-Net과 비슷함. 똑같이 대칭으로 만들어서 정보를 줌. 이렇게 하니까 정확도, 속도 모두 향상되더라.
5. Detection with Transformer

최근엔 자연어처리에서 transformer가 좋은 성능을 냈으니 CV에서도 사용해볼려고 시도하는 중. 이 외에도 box 개념을 왼쪽위를 중심좌표로 하는게 아닌 box의 중심좌표로 설정하려는 등의 시도도 있다.
(6강) CNN visualization
설계한 CNN 모델 내부를 들여다보는 디버그 및 분석 방법론들..
1. Visualizing CNN
우리가 설계는 했지만 막상 CNN 모델 내부 안에서 무슨일이 일어나는지 잘 몰랐다. 그걸 분석해보자. 그러니까 CNN layer에서 막 뽑아내서 본다던지, 입력 이미지를 부분만 가려서 어떻게 결과를 내놓는지 등 내부에서 어떻게 판단하고 내리는지..

낮은 레벨에선 대략적인 내용, 높은 레벨로 갈수록 구체적인 추상화된 내용들이 들어있더라.

여러 채널에 대해 그림처럼 나타낼 수 있는데 대략 이렇게 분석이 가능하다.

여러 분석 방법론들. 목적에 맞게 하던가 이런 종류가 있다는 것을 인지하자.
2. Analysis of model behaviors
2.1 Embedding feature analysis

입력 이미지 주고 6개의 이웃을 관찰. 어떤것을 중심으로 비슷하다고 판정하는지, 또 개 사진을 보면 자세에 상관없이 관련짓는 모습 등을 관찰할 수 있다.

비슷한 것 끼리 모아보는 방법론. t-SNE가 고차원의 것을 관찰 가능하도록 저차원으로 만드는 거라던데 그렇게 보면 대체로 비슷한 것들끼리 뭉쳐있음을 알 수 있다. 거리가 가까우면 둘이 헷갈린다는 거겠지.
2.2 Activation investigation

모델이 어느부분을 집중적으로 보는지 관찰하는 것. 위 예제에선 conv5의 138번째 채널에서 활성화된 부분을 mask로 해서 input image와 합쳐서 관찰. 그랬더니 어디에 주목하는지 또렷하게 보임.


이건 뭐냐면 feature에서 max해서 가장 높게 나온 위치가 있을거잖아? 그럼 그게 입력 이미지를 분석하는데 있어 제일 중요 요소로 잡은거기 때문에 그 feature가 acceptive field 한곳이 어딘가 보는거임.



이게 뭐냐면 모델이 어떤 class에 대해 대략적으로 어떻게 생각하는지를 분석하는거다.
하얀색(혹은 검정색) 이미지나 노이즈만 있는 이미지를 넣고 특정 class에 대해 가장 높은 점수를 주도록 해서 어떤 결과를 내놓는지 본다. 그럼 모델이 순수하게 생각하는 것을 뽑아낼 수 있다.


3. Model decision explanation
모델은 대체 어디를 보고 판단하는가.

일부분을 가리고 그 때의 점수를 확인해서 heatmap을 만든다. 그렇게 하면 어디부분을 중요하게 보는지 파악 가능하다.
 |
| [Simonyan et al.,CoRR 2013] |

결과에서 절대값 gradient(혹은 제곱)해서 높게 나온 값들을 시각화한다.


backpropagation-based saliency
Forward pass 할 때 relu를 사용하는데 음수는 0으로 없애는 방법이다. 이걸 거꾸로 돌릴 때 backpropagation 관점에서 보면 gradient해서 0으로 나온 값을 0으로 바꾸고 완전히 되돌리는 deconvnet 관점에서 보면 결과에서 나온 값을 0으로 바꾼다.

이걸 대략 식으로 나타내면 저렇게 됨.

근데 이 음수를 0으로 바꾸는 거를 2개를 합치면? 그냥 감각적으로 합친것 같다.

그래서 왜인지 모르겠지만 어디를 보는지 잘 알수 있더라.


Class activation mapping (CAM) 같은 경우 Global average pooling (GAP) 을 사용하는데 GAP은 한 채널을 몽땅 더해서 평균해서 하나의 노드를 만듦. Global average pooling (GAP) layer instead of the FC layer. CAM architecture with GAP.
CAMc(x,y) 앞에 아직 x,y를 더하지 않았다. 즉 아직 공간의 정보가 남아있어서 이미지 처럼 나타낼 수 있다.

이미지 처럼 나타내니 어느부분을 보고 class를 분류했는지 파악이 가능하다. 이건 혁신적인데 우리가 전에 물체 위치랑 그 물체가 뭔지 알아내려고 k anchor box 하면서 하던게 그냥 모델 안에 정보가 들어있던 거임. 그래서 다른 곳에서도 너무너무 쓰고 싶다. 하지만 문제가 있다.

이미 만들어진 모델 끝 부분을 도려내야 한다는 것. 마지막 layer 구성이 GAP과 FC layer로 이루어져야 한다. AlexNet 같은 경우는 Flattening해서 vector로 만들기 때문에 완전히 도려내서 다시 학습해야 하고 GoogLeNet은 global average pooling 과 FC로 이루어져있어 사용할 수 있다.
그래서 이걸 다른곳에서도 쓰고 싶다. 재학습 필요없이 미리 학습된 network에서 뽑아내고 싶다. 해서 나온게 Grad-CAM.
애초에 모델 상관없이 나오게끔 만든거라 어떤 모델에든 상관없이 앞이 CNN 이기만 하면 된다.

각 이미지 위치에 대해 각각의 class weight를 구하는 게 목적이다.

그래서 우리가 원래 했던 weight 정의에 따라 새로 구한다. 우리가 현재 관심있는 CNN부터 결과까지만 영향력을 구하면 된다.

좀 다른점은 더할 때 relu를 한다 함.

그래서 중간에 CNN이 있는 모델이기만 하면 되기때문에 모델에 상관없이 사용할 수 있다.

이걸 활용해서 만든게 scouter. 또 GAN도 만들 수 있더라.
실습
은 전 과제 하느라 못끝냄.
==========================
과제 / 퀴즈
======================
피어세션
실습에서 numel 함수가 도움이 될 수 있음.
skt 369. 기술서를 쓴다. 진짜 실력만 쓴다. 취업유리한 분야? 말고 제대로 된거 하나 있는게 중요.
깊게 하자. 코테를 본다.
능력이 될까말까. 절대적인 기준. 그래서 수시채용 등에도 딱히 to를 안둔다. it 대부분이 이러는듯.
경력기술서에 뭐했는지 적는게 있다.
산업공학과 출신한테 테일러 급수 물어봤음. 수학 어필해서 물어본듯.
=======================
후기
일찍 일어나자.
댓글 없음:
댓글 쓰기