==============================
학습내용
(7강) Instance/Panoptic segmentation
1. Instance segmentation

Instance segmentation이 뭔가? 각 픽셀에 대해 얘가 어떤 물체인지 아닌지만 구분하는 것.

RoI extraction through RoIAlign, an improved version of RoI Pooling. 원래 RoI 추출할 때 정수 단위로 나왔는데 소수점으로 바꿔서 내놓았다. 그래서 여기서도 성능 향상이 있었고 모델 마지막 부분에 mask용 layer를 붙였다. 그래서 원래 layer에서 나온 class를 mask layer가 참고하는 방식으로 만듦.
 |
| https://lilianweng.github.io/lil-log/2017/12/31/object-recognition-for-dummies-part-3.html |
그래서 실제 구조가 저렇게 비교된다.

저것도 이제 two-stage라 one-stage로 만든 YOLACT가 있는데, 주목할 부분은 Protonet. 진짜 mask를 만드는게 아닌 mask를 만들수 있는 기초 component를 만듬. Prediction Head에서 물체가 어떤것인지를 파악해서 Protonet과 결합할 때 mask의 component를 만들었으니까 이 component와 mask coefficients를 곱해서 해당 부분의 value만 남기고 이걸 더하거나 빼거나 해서 mask를 만든다. 이걸 결과로 내놓으면 해당 물체에 대한 mask가 나옴.

이것도 좀 무거워서 휴대용 기기에 올리려고 최적화 한 시도. 영상을 볼 때 key weight는 비슷하니까 다음 frame에서도 그 key weight를 사용할 수 있도록 넘겨준다. 그냥 계산 안하고 넘겨받으니까 성능 향상이 되더라. 근데 완전히 호환되는건 아니니까 깜빡이거나 하는 문제가 있긴 함.
2. Panoptic segmentation
그래서 배경에도 관심있지만 같은 class에 대해 각 물체를 구분 못하는 semantic segmentation 과 각 물체는 구별하지만 배경엔 관심없는 Instance segmentation 이 두개를 합치고 싶다. 그래서 합친게 Panoptic segmentation.

UPSNet이 그 중 하나인데 보면 말 그대로 Semantic Head와 Instance Head를 합친걸 볼 수 있다.

자세히 살피면 이렇게 됨.
Instance head에서도 객체를 검출하긴 하지만 객체에만 관심이 있기 때문에 잘라내고 저것만 나온 모습이다. 그래서 배경에도 관심이 있던 Semantic head와 결합해서 배경까지 포함하여 원래 bounding box로 나왔던 것을 mask로 바꿔주고 그 물체를 배경의 일부로 전체적인 모습을 보여준다. 완전한 배경은 Xstuff인데 그냥 그대로 합쳐준다고 한다.
그럼 Semantic head에서 물체만 나온게 아닌 알려지지 않은 unknown object가 있다고 한다. 얘내들도 보여주기 위해 여기에 물체라고 추출한 mask들을 빼줘서 나머지 베타적인 부분을 unknown class로 합쳐줄 수 있다.

이 UPSNet을 비디오로 확장한 VPSNet 도 있다. pi(init)라는 motion map이 motion map 에 따라서 mapping. 모든 픽셀에 대해서 다음 프레임에서 어디로 가는지 정보를 가지고 있다. 또 전 프레임에서 못봤던 특징이나 전에 있었는데 현재는 없는 특징 등도 관찰해서 더 정확한 detection 가능.
기존의 roi와 현재 roi로 추출된 index들을 tracking head를 통해 매칭함. 이걸 이용해 전 프레임에서 나왔던 물체와 현재 프레임에서 나왔던 물체와의 연관성을 확인한다. 즉 같은 물체인지 확인하는 것. index 매칭.
3. Landmark localization
landmark는 물체를 추출하는데 중요한 부분. 이걸 추척하는 것.

원래는 고전적인 방법으로 사람이 추출했음. keypoint 가 N개 있고 (x,y) 좌표를 가진다면 2N개를 가지고 있는 FC. 근데 안좋다는게 알려지면서 각 keypoint를 서로 다른 class라고 가정해서 모든 pixel마다 그게 keypoint인지 아닌지로 문제를 해결하는 heatmap classification 방법이 고안됨. 하지만 이건 말 그대로 모든 pixel에 대해 고려하기 때문에 계산량이 많다.
landmark 하나가 (x,y) 이런 식의 label로 주어졌을 때 heatmap label도 생성해야 한다. location에서 heatmap으로 어떻게 변환할 것인가.

근데 이건 location에서 heatmap 으로 변환한건데 이 heapmap으로 나온걸 우리가 사용 가능한 좌표형태로 나와야 하는데 즉, heatmap에서 location으로 변환되도록 하는것도 해야 함.
Gaussian을 하는 이유?는 keypoint가 딱 한 점 여기! 로 끝내는 것 보다는 좀 더 퍼지게끔 하려고 한 거인듯.

Hourglass network라고 해서 입력 이미지를 통과시켜주면 keypoint heatmap이 나오는 것 같음. 이걸 여러번 중첩할수록 또렷해진다. 그림이 그렇잖아..
저렇게 모래시계처럼 가운데로 줄어드는 이유는 receptive field를 늘릴려고. 그래서 이미지 사이즈 줄인걸 다시 키우는데 여기도 U-Net이나 FPN처럼 skip connection이 있다. 이걸 이용해서 이미지 사이즈를 키워줌.

근데 자세히 보면 구조가 약간 다름. U-Net과 달리 skip connection을 더해줄 때 concat으로 해서 차원수를 늘리는게 아닌 진짜 더해줌. 그리고 skip connection을 통과할 때 그냥 가는게 아니라 convolution layer를 통과시켜 준다. 그래서 U-Net보단 FPN에 가까운 모델이다.


그래서 입력과 출력 관계 모델을 잘 구현만 하면 2d용 conv 가지고 3d도 잘 표현할 수 있다. 이런 내용인 것 같음.

backbone 모델은 같으니까 관심있는 모델 아무거나 다 집어넣을 수 있다. 저건 다 집어넣은거.
다 집어넣으면 장점이 하나의 이미지에 대해 다양한 방법으로 분석해서 좋아진다는 것 같음.
4. Detecting objects as keypoints

CornerNet은 각 왼쪽위, 오른쪽아래 점들을 추정하게 한 다음 그 점들의 정보를 Embeddings해서 담는다. 영상을 주면 corner point만 잔뜩 추출하고 embedding point는 같은 object에서 나왔다면 같아야 한다 라는 조건을 걸어주고 학습을 함.
출력값을 줄여 정확도에 집중한다기 보단 속도에 집중했다.

근데 이렇게 하니 중앙점이 중요한 역할을 한다. 그러니 bounding box 조건을 좀 바꾸자. 해서 중앙과 width, height로 바꿈.

성능이 더 좋다.
요약
task들이 대부분 비슷한 디자인 패턴을 가져서 맨땅에 헤딩해서 만들기 보단 기존에 있던거를 기반해서 만들면 쉽다.
데이터나 출력을 변경하는 것으로 속도나 성능향상을 크게 가져올 수 있다. 즉 데이터 표현이 중요한다. 이를 통해 어떻게 설계하면 되겠다. 가는 감을 느끼길..
(8강) Conditional generative model
1. Conditional generative model

주어진 조건에 따라 생성하는 것. 문장을 번역하는 것과 비슷하다.
이미지 뿐만 아니라 소리, 번역 등에도 사용될 수 있다.

기본적으로는 전에 배웠던 Generator와 Discriminator로 만든 것과 같다. 서로 성능이 올라가며 모델 성능 전체가 올라가는거.

그래서 Conditional GAN과의 차이점은 입력 Condition이 추가되었다는 것임.
그럼 이미지 해상도를 높여주는 Super Resolution GAN을 예시로써 보자.


SR GAN을 통해 이것이 기존에 했던 다른 Naive Regression model 과의 차이점이 뭐냐면 loss func 대신 Discriminator를 넣은 것이다.
 |
| [Ledig etal.,CVPR2017] |
왜 그래야 했는지 살펴보자. loss 같은 경우 MAE나 MSE를 사용하는데 이건 각각의 추정값과 결과 label의 차이들을 평균해서 계산함. 근데 이렇게 하면 모델은 가장 안전한 결과인 정말 만들어진 모든 그림에 대한 평균값으로 만들게 된다. 어정쩡하게 만들어져서 흐려짐.
이를 방지하기 위해 "해당 위치엔 이게 있어야 한다" 라는 명확한 답을 참값으로써 모델이 인식하고 그런 쪽으로 학습을 해야함. 이걸 해주는게 Discriminator라고 생각한다.


그래서 loss를 어떻게 잘 설계한 것보다 Discriminator로 한게 잘 되더라.
2. Image translation GANs

GAN이 CNN으로써 처음 고안된게 Pix2Pix인데 위에서 Loss 쓰면 안좋다고 했지만 써야했던 두가지 이유가 있었다. 첫번째는 Discriminator는 x랑 y가 참인지 거짓인지만 가리는거리 label인 y와의 직접적인 비교가 없다. 그래서 직접적으로 비교해주는 (밑에 -식으로 비교하잖음) 식이 필요했던거고 두번째는 저게 옛날거라 Discriminator만으로는 불안했었다고 한다.
그리고 기존의 GAN loss 즉, 기존의 GAN adverse loss와의 차이점은 뒤에 Ex,z[log(1-D(x,G(x,z))] 에서 G에 z뿐만 아니라 x도 들어간다는 것. (무슨말인지 모르겠다.)

결과. 그냥 사진에선 잘 되는데 colorization에선 실패한듯.

또 Pix2Pix의 단점이 두 데이터셋이 항상 pairwise data여야 한다는 것이다. 하지만 그런 데이터셋은 많지 않다. 그래서 pair 하지 않고도 만들어낼 수 있도록 만들자 한게 CycleGAN. 그래서 CycleGAN은 pairwise datasets이 아니어도 변환이 가능하다.

그래서 pairwise 아니어도 가능하게 하기 위해 기존 GAN loss에 Cycle-consistency loss가 추가됨. 그럼 이거 어떻게 하느냐. 사실 말이 안되지 않느냐. 그래서 변환하고 원래 입력으로 다시 변환해서 이 둘이 같아야 한다. 이 조건을 만족하면서 변환할 때 discriminator를 속이는 방식으로 하면 결국 이상적인 CycleGAN모델이 만들어짐

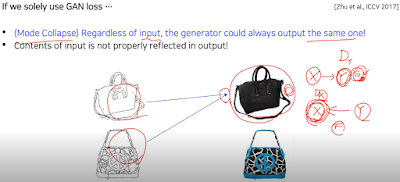

그래서 안의 content도 유치가 되야 한다. 라고 Cycle-consistency loss 도 사용한다.
근데 문제점을 제기할 수 있음. GAN이 훈련하기 너무 어렵다. 단순히 이미지만 만들면 되는건데 Generator, Discriminator 만들고 둘 다 훈련하고 너무 복잡하고 어려운거 아니냐? GAN 없이 높은 퀄리티의 이미지를 만들 순 없을까? 해서 나온게 Perceptual loss다.


사전 학습된 모델의 early layer. 사람이 자각하는 방식과 비슷하다.

이런걸 할거다.

입력 이미지를 변환시키는 모델에 넣음. 어떤 스타일로 변하는지는 한가지 밖에 못정하고 데이터에 따라 달렸음. 미리 학습된 VGG-16에다가 넣어줘서 여러 activation 들을 뽑아낸다고 한다. 중요한건 VGG-16은 훈련하는게 아니기 때문에 고정시켜줌.

두가지 loss를 사용할거다. 우리가 원하는 변환효과를 제대로 적용하도록 하는 Style Target, 입력 이미지 상태를 유지하고 있는지 Content Target.
Content Target부터 살펴보면 입력 이미지가 Transformed Image를 통해 변환될텐데 입력이미지를 어느정도 유지하도록 한다. 그래서 입력 이미지가 같은걸 볼 수 있다. 두개를 VGG를 통해 loss를 계산한다고 한다.

좀 어려울 수 있는데 나도 정리하면서 적어보겠다.
입력 이미지가 변해도 원래 이미지 형태는 유지할 수 있도록 Content Target에도 같은 입력 이미지를 넣었다. 그럼 위에서 봤던 예시처럼 Style도 변해야 한다. 얜 어떻게 하느냐?
근데 중요한 특징이 있는데 Style은 위치 좌표에는 무관하다는 것이다. 즉 결과로 나온 Feature maps는 H,W,C 로 3차원이 나오지만 H,W 는 필요없는 것. 그래서 summation으로 polling을 한다. H와 W를 펴서 C,H*W 로 만든다.


그래서 (C,H*W) * (H*W,C) 의 행렬곱으로 (C*C) 의 Gram matrix를 만든다.
그럼 Channel이 의미하는게 뭔지 생각해보자. 각각의 Channel은 고유의 detector 역할을 한다고 배웠다. 어떤 channel은 동그라미, 어떤 channel은 세로줄, 어떤 channel은 가로줄.. 의 역할을 한다고 가정하자. 이 각 channel들의 상관관계를 알 수 있다. 즉 세로줄이랑 동그라미랑 동시에 같이 나오는 경우는 동그라미를 담당하는 channel의 index와 세로줄을 담당하는 channel의 index matrix를 보면 값이 높게 나올 것이다. 반면 동그라미랑 가로줄이랑 동시에 잘 안나오면 해당 matrix의 값은 작을 것. 이런식의 style적인 상관관계를 알 수 있다. 패턴들 간의 경향성을 학습하는 것.

이거를 단순하게 하나의 convolution layer에서만 gram matrix를 뽑고 이 2개 사이의 차이를 구해서 loss를 measure 하는게 아니라 중간중간에 channel을 다 뽑아서 여러군데에서, 서로 다른 level에서 style loss를 measure를 한다. (질문하자.)
style을 encoding 한 것. 이런 style을 참조햇으면 좋겠어 하고 style target을 걸어주면 그에 따르도록 학습이 된다.
그래서 super resolution같이 style target을 사용안하고 content target만 사용하는 예시도 있다. 그래서 목적 모델에 따라 다르다.
3. Various GAN applications
정말 다양한 여러 분야에 활용 가능하다(ppt 보자.).
==================================
퀴즈 / 과제
아마 오늘 못할듯.
=========================
피어세션
GNN 여기보고 이해하자.
https://glassboxmedicine.com/2020/05/29/grad-cam-visual-explanations-from-deep-networks/#:~:text=Grad%2DCAM%20is%20a%20form,and%20the%20parameters%20are%20fixed
조교님이 소개해주신 최신 논문을 볼 수 있는 사이트
https://paperswithcode.com/
==========================
조교 세션
register_forward_hook 이랑 register_hook 은 다르지 않나요??
https://pytorch.org/docs/stable/autograd.html?highlight=register_hook#torch.Tensor.register_hook
참고하시면 좋을것같습니다
분기점이 없다면 동일하다고 함
Stacked Hourglass Network는 키포인트 추정 알고리즘에서 ResNet처럼 대중적으로 쓰이는 backbone으로 알고있는데 구조가 FPN과 매우 유사해보입니다. Hourglass Network와 FPN의 차이가 무엇인지 또 특히나 키포인트 추정에서 성능이 뛰어난 이유가 궁금합니다!
FPN은 여러 사람 얼굴 있을때 얼굴 크기가 다 다르니까 이미지 크기가 다양할 때 좋음.
반면 Hourglass는 비교적 고정된 크기의 이미지에서 정확도를 높이겠다는 목적.
DensePose 모델의 경우 2차원 이미지를 입력으로 받아서 출력하는건데 출력 이미지를 보면 3차원으로 해석하는 것 처럼 보입니다. 진짜 3차원 정보를 담고있는건지 아니면 그림만 그럴듯하고 2차원 정보만 담고있는건지.. 또 U랑 V 데이터는 어떻게 해석해야 할지 잘 모르겠습니다.
3차원 예측 목적이 맞다. 사람의 경우 모양이 어느정도 고정되어 있으니까 가능하지 않을까..
Grad-CAM에서 weight 구할 때 왜 gradient를 활용하나요? gradient가 큰거랑 네트워크가 집중하는 부분이랑 무슨 상관인지 궁금합니다.
gradient가 크면 결과에 영향을 많이 미치는 부분이니까 중요한 부분이라고 판단. 이건 다른 모델에서도 같음.
=============================
후기
강의 배속 1.5배속으로 들으니 신세계다.
앞으로도 이렇게 해볼까..
댓글 없음:
댓글 쓰기