=======================================
학습내용
(9강) Multi-modal: Captioning and speaking
1. Overview of multi-modal learning
멀티모델이 뭔가. 이번주 지금까지 시각에 대해 배웠지만, 시각뿐 아니라 청각, 촉각, 미각.. 같은 오감이나 사회적 관계, 사전지식, 텍스트 등 다른 여러 모델도 함께 쓰일 수 있음. 여기에 관해 3가지 어려움이 있다.
첫번째 어려움은 표현하는 방식. 우리가 소리는 주파수와 진폭으로 화면에 표시, 시각은 rgb 0~255로 표시, 텍스트는 embedding vector로 바꾸긴 하지만 이건 사람이 정해서 하는거라 한계가 있다.
두번째는 Unbalance between heterogeneous feature spaces. 다른 감각들간 상호작용이 1:1로 딱 안맞는다.

세번째는 모델을 같이 사용했을 때 특정 모델에 bias 되는 현상.
 |
| [Wangetal.,CVPR2020] |
예를 들어 액션을 학습한다고 하자. 사람은 배우의 표정과 행동, 소리를 듣고 얘가 뭘 하고 있다고 파악하지만 소리도 듣고 파악을 한다. 모델도 시각과 청각 모델 두개를 놓고 학습해도 사실 화면만 보고도 판단할 수 있는 경우가 많으니 학습할수록 소리보단 이미지모델에 치중되서 학습한다. 즉 나중엔 소리모델이 제대로 역할을 못함.

그래도 사용한다. 정말 좋을 것 같거든.
2. Multi-modal tasks (1) - Visual data & Text
들어가기 전에 전에 자연어 처리했던거 간단히 복습해보자.
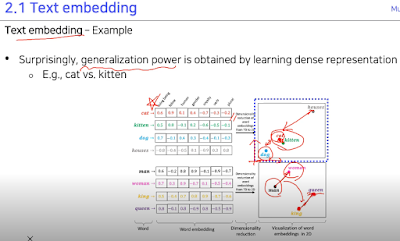
각 단어의 embedding vector는 각 element가 정보를 가지고 있고 단어의 거리를 이용해 비슷한 애들끼리는 뭉쳐있고 거리관계가 비슷하고 등..

그래서 word2vec 모델에선 고양이다! 고 하면 고양이 부분의 one-hot vector만 1로 하면 embedding vector에서 고양이에 해당하는 부분만 활성화 시켜서 그 부분에 대해서만 학습하는 것 같다.

뭘 학습하냐면 주변 단어와의 관계를 학습함.
2.1 Matching

그럼 multimodal 중 matching 부터 보자.

두 개의 모델을 거쳐서 나올 때 합치기 위해 d차원 embedding vector로 맞춰주고 합친다.

둘이 관계 있는 텍스트와 이미지는 서로 가까워지도록, 관계 없는 사이는 멀어지도록 학습한다.

 |
| [Marinetal.,TPAMI2019] |
그럼 이런것들도 가능해진다. 이미지와 텍스트 간의 사이가 연결되어 있기 때문에 가한 것.

유사한 loss는 cosine 유사도로 점검한다. 이 loss가 joint embedding 에 대한 loss. 이것만으로는 부족하다고 semantic regularization loss를 쓴다고 한다. 전체 정보에서 일부의 정보만이라도 일단은 중요하게 catch했으면 좋겠다. 라고 한다.
2.2 Translating

다음은 translating. 이미 한 모델을 거쳐서 번역한 거를 이용해 출력에 사용하는 거다.

이미지 설명하는 CNN모델, 텍스트 출력하는 RNN모델 완전히 다른 2모델이 있다고 하자. 내가 하고싶은건 이 두 모델을 이용해서 이미지를 주면 그걸 설명해주는 텍스트를 만들고 싶다.
 |
| [Vinyals et al.,CVPR2015] |
 |
| [Xu et al.,ICML2015] |
어딜 보고 말해야되나. 하는 문제가 생긴다. 그건 전 시간에 했던 heatmap과 비슷하게 한다고 한다.

사람도 물체를 보면 전부다 훑어보는게 아니라 주요 특징들을 위주로 본다. 우리가 전 시간에 했던 작업이 이미지를 보면 물체 어디를 보는지 표현하는 heatmap이었는데 이걸 이용한다고 한다. Features in grid 안에 있는 attention들을 probability라고 생각하고 attention엔 각 위치에 집중을 할건지 안할건지가 들어있다고 함. 각 위치를 행렬곱 으로 하고 더해서 평균낸다. 그래서 Z가 나온다.

Feature vector를 LSTM의 condition으로 넣어준다. 어디부분을 중요하게 할지 spatial attention을 출력하고 이 weight를 feature map 과의 inner product를 해서 pixel dimensional vector z를 만들게 된다. 이게 z1.

위에서 만든 z1을 RNN의 condition으로 하고 시작단어 y1를 입력으로 넣어준다. condition이 주어졌을 때 뭘 말해야 되나 고민을 한다. 그래서 결과가 나오면 결과 단어랑 다음에 어디를 referencing 할지도 같이 예측해줌. soft attention map으로 어떤부분을 attention 해줘야 하나.

결과로 나온 s2를 feature map 과 weighted sum 를 해서 z2를 만들고 y2는 이전에 출력했던걸 넣어줌.

반대로도 가능. 즉 텍스트를 주면 이미지로 내놓는것도 가능한데 텍스트 1개를 주면 수많은 이미지가 나올 수 있다. 이런문제는 그냥 generative model로써 푸는게 낫다.

텍스트를 주면 embedding vector로 만들고 앞에 가우시안 랜덤 값을 넣어줌. 하나만 생성하지 말고 비슷한 여러개 생성하라고. 결국 이 문제는 텍스트가 condition이 된 상태에서 이미지를 만들라는게 된다. 이 Generator를 겨처서 이미지 만들고 Discriminator를 거침. 근데 입력문장도 같이 줘서 가짜냐 진짜냐를 학습시킴.
2.3 Referencing


Image stream이랑 Question stream으로 나눠서 스스로 이미지를 보고 질문에 답하는 모델을 만든다. 둘이 연결할 때 전에 했던것들과 마찬가지로 차원을 맞춘다.
3. Multi-modal tasks (2) - Visual data & Audio
소리 시각화 방법에 Waveform, Power spectrum, Spectrogram이 있다.

Power spectrum의 경우 세로축은 진폭으로 Waveform과 같지만 가로축이 시간이 아닌 진동수다 (Magnitude 찾아보니까 Amplitude의 절대값. 양만 고려하는 듯.). 그런데 가로축이 진동수로 시간에 대해서 표현을 못하잖아? 그래서 window를 사용한다.
일정 크기 구간, 여기선 A사이즈 만큼의 window에 대해서만 Power spectrum을 구하고 이걸 B만큼 오른쪽으로 이동시킨다. 이런 방식으로 시간에 대해서도 구할 수 있다.
Hamming window의 경우 이렇게 window로 잘랐을 때 인공적으로 자른거니까 소리가 갑자기 시작되고 갑자기 끝난다. 그래서 계산하는데 잡음이 생긴다. 이를 방지하기 위해 시작과 끝쪽엔 weight를 적게 주고 가운데 weight에 집중하는데 이걸 원래 소리와 선형곱해줘서 가운데에 집중할 수 있게 해준다.
이렇게 하는걸 Fourier transform(FT) 이라고 하고 window로 작은 부분만 변환해주니까 Short-time Fourier transform(STFT) 라고 하는것 같다. 이걸 왜 하냐?

이렇게 주파수를 가로, 진폭을 세로축으로 두면 어떤 크기의 주파수가 존재하는지 한번에 파악이 가능하다.

그래서 이걸 위에서 window 방식으로 시간대별로 나열하면 다음과 같이 시간에 따른 주파수와 진폭을 볼 수 있다.
3.2 Matching(Joint embedding)


소리만 듣고 내가 어디있게? 맞추기

학습 방법은 비디오가 있으면 영상만 따로 소리만 따로 분리한다. 영상은 pre-trained 된 모델을 사용하고 고정시켜 학습하지 않는다. 소리부분을 가지고 와서 conv layer에 넣는다. 영상에서 Object Distribution에 대한 conv, Scene Distribution에 대한 conv 부분으로 분리해서 각각의 loss를 KL로 계산. 근데 위에서 열심히 설명한 Spectrogram을 안쓰고 왜 쌩 wav를 쓰냐? 그냥 옛날이라 별 생각 없었던듯.. 그래서 최신 논문들은 wav말고 다른거 쓴다.

그래서 영상 말고 내가 소리의 특징에 대해서만 따로 연구하고 학습하고 싶다. 고 하면 pool5 쯤에서 따로 떼와 모델 통과시키면서 연구하면 된다. 왜 conv8에서 가져오면 안되냐면 conv8로 갈 때 쯤은 이미 object distribution과 scene distribution쪽으로 weight가 바뀌어 있기 때문에 conv5 쯤이 좀 general 한 곳일 것이다.
3.3 Cross model translation


VGG-Face Model 이라고 사람 얼굴을 주면 그 사람의 무표정한 정면 사진을 출력하는 pre-trained model을 사용함.

모델 Speech2Face Model의 목적이 소리만 듣고 그 사람의 얼굴을 파악하는 거다. 그래서 소리만 듣고 학습하는 모델을 만드는데 이게 위에서 사용한 VGG-Face Model의 output 과 비슷하도록 둘의 차이를 loss로 만들어 학습시킨다. 이렇게 하면 우리가 만든 모델이 소리만 듣고 VGG-Face Model의 output을 모방하여 나오게 되므로 그대로 Face Decoder에 넣어 얼굴이 나오게 된다.

다음은 이미지에서 소리가 나오는 모델을 만들려고 한다. 바로 뽑아내는게 아니라 중간에 단어를 만들고, 그 단어를 가지고 소리를 만들어내는 단계 즉 2개의 모델을 사용해서 만든다고 한다.
특이한 점은 이미지에서 단어를 뽑아내는 모델을 만들 때 완전한 단어를 쓰는게 아니라 아직 단어화 하지 않은 중간 token을 쓴다고 한다. 아마 결과로 나온 embedding vector를 word로 변환하지 않고 그대로 쓰는게 아닐까 싶다.
그럼 이렇게 나온 vector를 소리로 내보내는 모델에 넣어 출력한다. 즉 text to speech 모델에 넣음.

바로 할 순 없으니 speech를 받으면 unit이 나오는 network를 구성해주고 유닛이 들어가서 사용이 되야 된다. 그럼 unit이 들어가면 speech가 나올 수 있게 되었다. 그래서 두 모델이 반으로 나뉘어 따로 학습을 하지만 호환성이 이루어지면 end to end로 학습이 가능. 물론 end to end라고 한번에 다 쓰겠다는 뜻은 아니다.
3.4 Cross modal reasoning

Sound source localization



이미지를 보고 이 소리가 어디에서 나는건지 예측하는 모델. 원래 입력 이미지랑 입력 사운드를 준다. 그리고 이미지에서 해당 소리가 나는 곳에 highlight를 해주고 여기에서 소리가 난다고 label을 정해줘서 loss를 정해주고 훈련을 했었다. 이 부분이 Attention net 부분. 보면 해당 물체에 score가 제일 높다. 이건 Visual net에서 나온 weight map에 Audio net에서 나온 weight map을 모든 visual weight map에 선형곱을 해줘서 나온 score 값을 표시하는 것이다. 이걸 사람이 만든 답인 label과 비교해서 학습했다.
근데 우리가 전시간에 물체에 대한 heatmap을 나타내는 법을 배웠다. 보통 영상은 그 영상의 물체 소리가 그 영상에서 나오는 거니까 물체 위치를 추출하는 heatmap을 이용해서 물체 위치랑 소리를 이용해 스스로 학습하게 할 수 있을것 같다. 즉 unsupervised learn이 가능하다.
Attended visual feature는 결과로 나온 Localization Score을 weight로 사용하고 spatial feature vector하고 직접 element wise를 쭉 곱한 다음에 다 평균을 내준다. weighted sum pooling. Audio net 에서 나온 feature와 이렇게 나온 Attended visual feature가 같아야 한다고 학습이 되야 한다. 영상과 음악이 다른곳에서 나왔다고 하면 달라야 한다고 훈련이 되어야 한다.
근데 Attended visual feature랑 sound feature와 같게하는 이유는 뭘까? 일단 sound feature는 전체적인 encoding을 다 하고 있을 것. Attended visual feature는 원하고자 하는 물체에 대해 가지고 있는 것. 저 목적하고자 하는 물체 부분을 feature를 pooling 해온다. 목적하는 부분의 weight가 크게되서 이 부분을 Attended visual feature이 가지고 있다. 이런 정보가 담겨있는 Attended visual feature와 sound feature가 닮았으면 좋겠다. 그래서 다른 영상이 실행되도 그 영상에서 소리가 들리면 주로 같이 발생하는 visual feature가 여기더라 라는 두개의 fearue가 비슷해지더라.

지도학습 loss도 같이 쓸 수 있겠지.

또 다른 모델로는 영상 안에 다른사람 2명이 말하고 있을때 해당 사람의 목소리만 추출하는 형태의 모델이다. 사실 이런 훈련을 시키려면 각 사람의 순수한 말을 추출해야 하기 때문에 두 영상을 합치는 형태로 영상을 합성하여 훈련시키는 방식으로 한다.
그 외에도 말에 따라 입이 움직이는 것도 있다..
(9강 실습) Image captioning

pre-trained 된 resnet101을 쓸건데 마지막 레이어 2개는 class 분류하는 FC이니 잘라내고 마지막 CNN 만 쓰겠다. 이 CNN을 가지고 RNN에 넣어서 문장 만들겠다. 하는게 목적. 그래서 잘라냄.
보면 사이즈가 14인데 이는 입력 이미지가 정해져 있긴 하지만 어쨋든 CNN 에서의 이미지 사이즈는 14로 맞춘거다.

단어와 attention 정보를 함께 입력으로. 매 순간마다 어디를 봐야할지.

각 출력에 대해 greedy 하게 무조건 max값만 출력하면 다른게 더 나았을 수도 있다.. 하는 여지가 생겨서 Beam search를 만들었다.
10000개의 단어 중에 어떤 단어를 가져올 거냐. k=3 이라면 처음엔 top 3를 가져온다. 이 각각의 단어 다음의 경우에도 top 3를 검사한다. 그럼 총 9개 가 나오는데 여기서 top 3를 본다. 즉 나머지 6개는 지우고 최종적으로 3개가 나옴. 이걸 반복함. 문장이 끝날 때에는 <end> 토큰 중 제일 점수가 높은걸로.
https://github.com/sgrvinod/a-PyTorch-Tutorial-to-Image-Captioning
(10강) 3D understanding
1. Seeing the world in 3D perspective
3D 공간에 대한 이해가 중요!
가상세계 경험하게 해주는, 3D 프린팅으로 제품, 건물짓기, 수학적, 화학적 활용분야(단백질 분석 등).
우린 3D 세상에 살지만 3D에 투영된 2D를 보고 산다. 카메라도 그냥 3D를 2D로 projection 한 것.
근데 극복할 점은 같은 물체 다른 각도 사진 2장을 이용하면 3D로 복구 가능. multiple view로 확장가능. 관심있으면 "Multiple view Geometry in computer vision, Richard Hartley and Andrew Zisserman." 이라는 거의 유일무이한 바이블이 있음. 난이도는 좀 있다.
컴퓨터에선 rgb 2D array로 봄. color가 있다면 multi channel로.

3D는 multi image로 저장하는 방법, Volumetric 형태 방법, 간단한 도형들의 집합 Part assembly, 3D point틀의 집합 Point cloud ((x,y,z) 리스트로 표현됨.), Mesh (Graph CNN) 게임에서 많이 보던 삼각형 방식. (x,y,z) 포인트로 한 삼각형 edge, vertex, Implicit shape/function 3D를 고차원의 형태로 표현하고 0과 겹치는 걸로 표현 (공간상의 구를 식으로 표현하는 형태 등을 생각하면 편할듯.).
3D 데이터 셋으로는
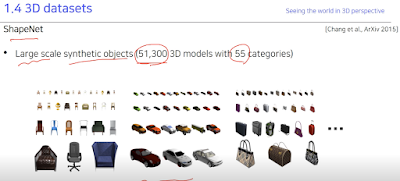
ShapeNet. 55개 카테고리의 51,300 물체들.

PartNet(ShapeNetPart2019).

SceneNet.

ScanNet. 실제 스캔이라 비교적 많은거다.

Outdoor 3D 데이터셋들... 대부분은 자율주행 관련 데이터셋이다.
2. 3D tasks
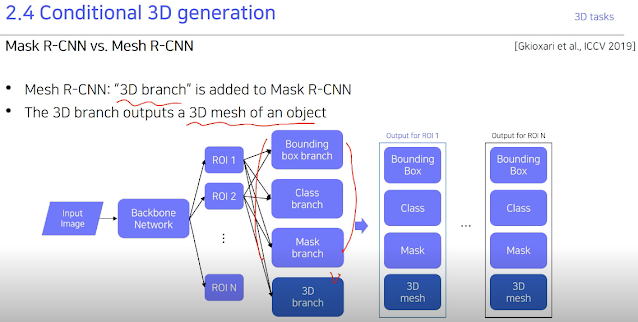
기존에 했던 Detection, segmentation 등등.. 다 가능하다. 3D에서의 Mask R-CNN인 Mesh R-CNN도 기존에서 3D branch가 추가된것.

depth를 먼저 추가하며 물리적으로 의미있는 것을 뽑아낸다. 2.5D Sketches를 통해 사람이 인지할 수 있는 형태 추출.
그래서 이런 3D 인지는 자율주행에 매우 중요하다.
3. 3D application example
Defocusing a photo using depth map

after-refocusing 만드려고 함.
진행방식

1. 우리가 focus 하고싶은 범위를 정함. Dmin부터 Dmax까지. depth 거리. 여기 예제에선 Dmax 이후엔 focus를 다 날리겠다고 단순화함.
2. thresholding 해서 mask를 정함. Dmax 안쪽은 focusing area, 바깥쪽은 defocusing area.
3. 전체 input image blurred version 만듬.
4. mask focus image와 masked defocused image 만듬.
5. 이 두개를 blending.
그냥 ppt 보고 하자.
================================
마스터세션
구체적인 모델명들 많이 조언해줌.
===========================
피어세션
수업내용 복습함.
============================
후기
열심히 해야겠다와 권태기가 온 것 같다. 그래도 열심히 하자.
댓글 없음:
댓글 쓰기